Along with the development of OtoNhanh.vn, datasets from automobile industry and users of our site become tremendous. This motivates us to find more efficient training strategies. In OtoNhanh.vn, TensorFlow has become our preferable deep learning library for a variety of reasons, one of them is that TensorFlow supports strongly Distributed Training, which is very important in production up-scaling. In this blog, I will briefly introduce Distributed TensorFlow and the way we apply it in our business.
I. Basic definitions in Distributed Computing
Model Parallelism versus Data Parallelism
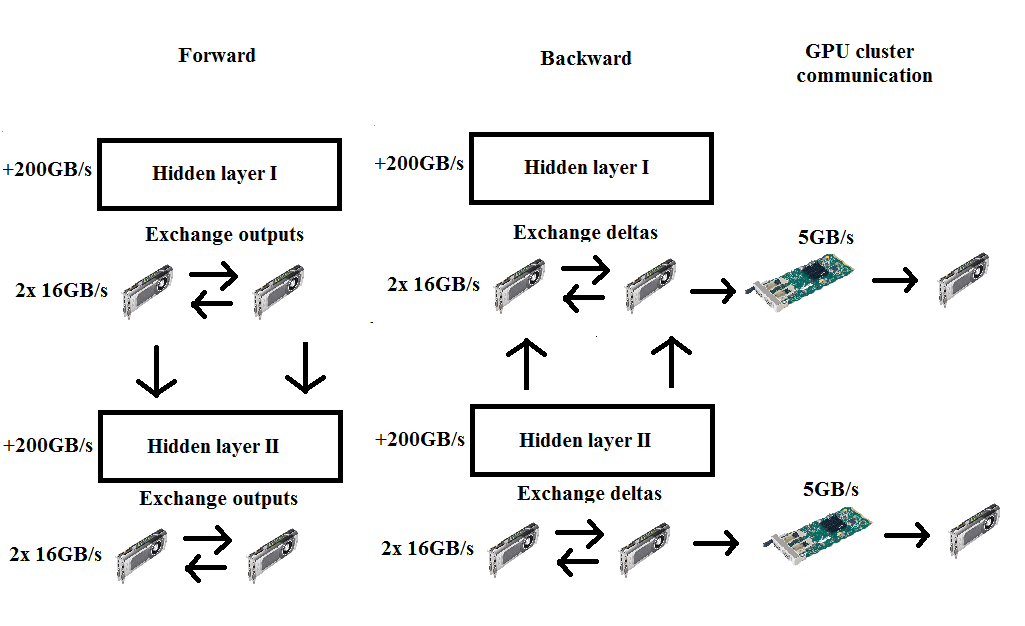
They are two popular styles in Parallelism Computing, which solve different problems in Deep Learning training. First, we talk about Model Parallelism. A very first example of this method can be found in this famous article. In this Alex-Net, the model is too big for a single GPU, so the authors employed it in two GPUs: some parts of the graph reside in a GPU, while the others stay in the other GPU. In model parallelism, we split the whole graph among GPUs and use the same data for each GPU: each GPU will compute the gradient for some variables of the model using the same data.
{kind=link}
The advantage of this approach is quite apparent: it helps us to deal with the large architecture which cannot be fitted in a single GPU. Nevertheless, we have to wait for every node in the network to complete their computing before starting another step. A solution for this bottleneck is the Synthetic Gradient method that was developed in last year. In OtoNhanh.vn, especially in Computer Vision lab, this benefit is limited. All the architectures are able to reside in a single GPU and we don’t have a desire to expand in order to avoid Over-fitting.
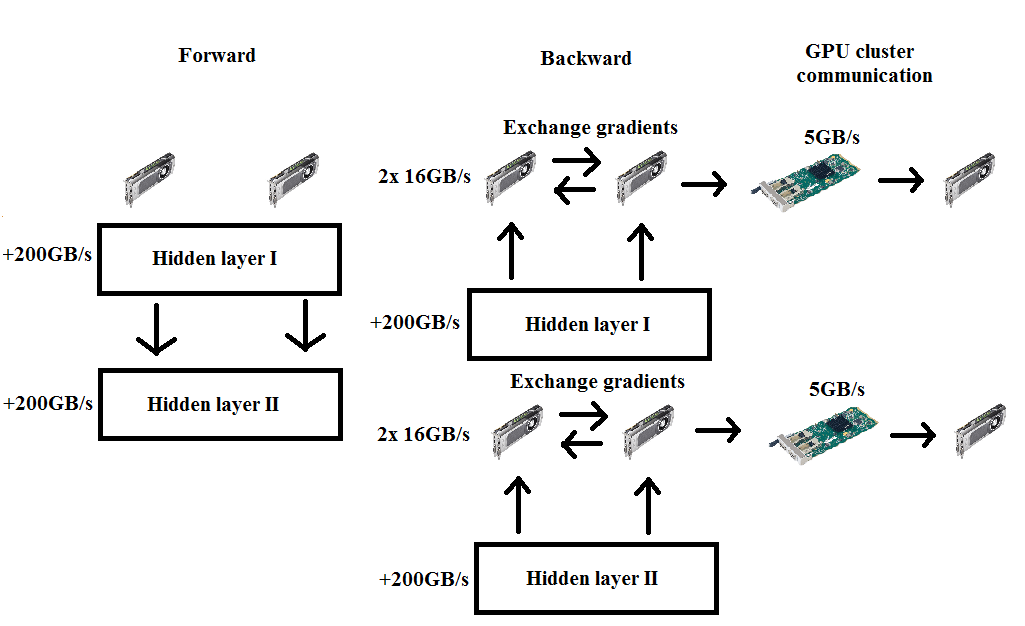
In contrast, Data Parallelism fixes the same graph in every GPUs in the network but uses different data batches for each GPU, then do some aggregation to combine the gradients from different GPUs. This approach helps us to slide over the whole data-set faster, e.g, finish an epoch in a shorter time. In fact, Data Parallelism gains more attention from the community and the rest of this blog, we will talk about the technique used in this approach.
{kind=link}
At the moment, Data Parallelism is heavily employed by OtoNhanh.vn when we train our Computer Vision models using cloud services of Amazon (AWS).
Method of Aggregation
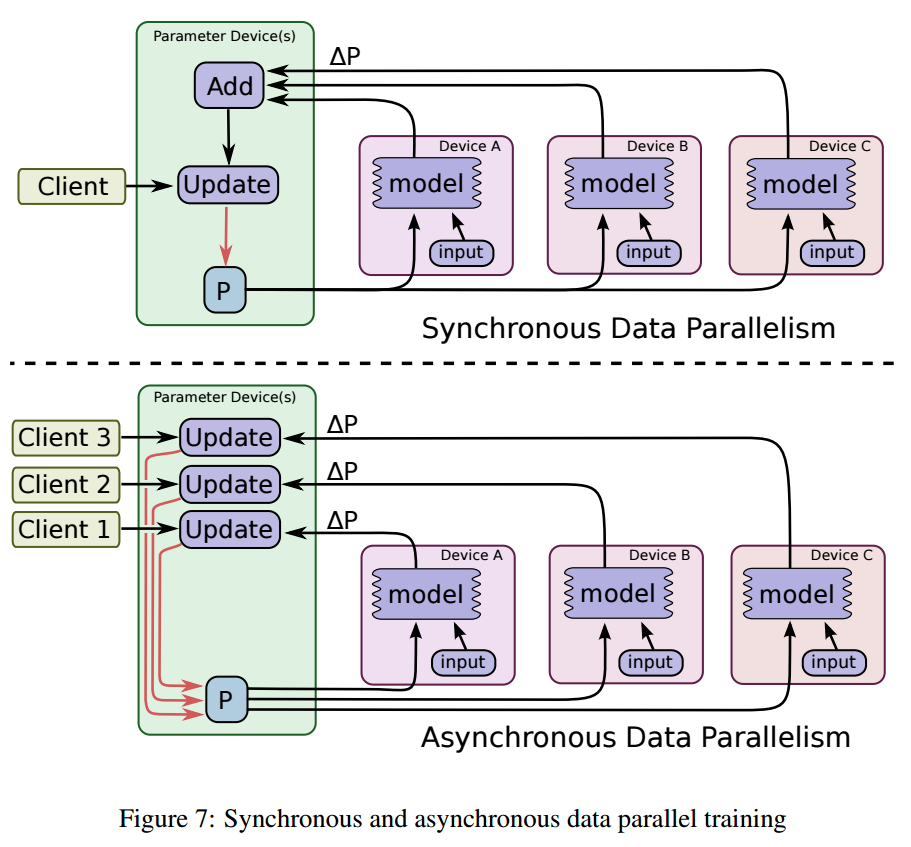
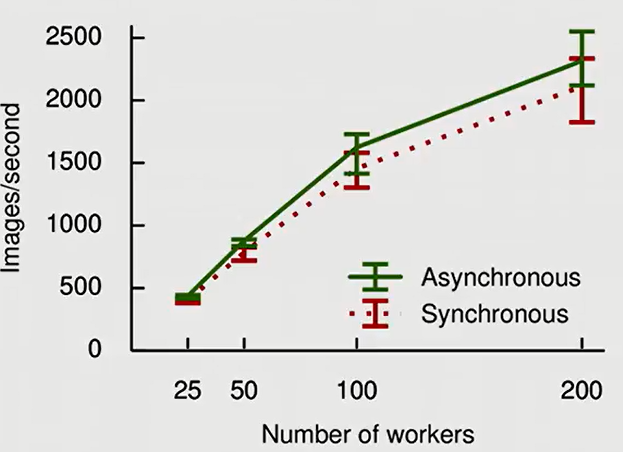
In Data Parallelism mechanism, each GPU will compute its own gradients of the whole graph. So we have to think a way to combine all these gradients for the update of the parameter. There are 2 settings: Synchronous Data Parallelism and Asynchronous Data Parallelism. In synchronized setting, several data batches are processed simultaneously. Once all the local backprops are finished, the local gradients are averaged and we performed the update. We can see the bottleneck here: the overall computation speed of the system equals to the weakest worker in the network.
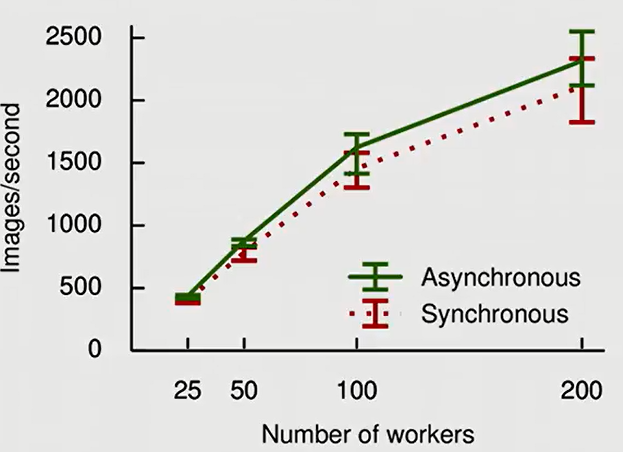
In asynchronized setting, once a GPU finishes its computation, we will use its gradient to update the model immediately. As we can see, in a system of N workers, the number of updates in asynchronized setting is N times greater than that of synchronized setting.
{kind=link}
Personally, I think asynchronised setting is more optimal: Its performance is comparable to synchronized version while its speed is understandably superior.
{kind=link}
II. Distributed TensorFlow
In this part, I will give a bottom-up introduction about the distributed mechanism offered by TensorFlow. Four main pillars of Distributed TensorFlow are:
- Model replication
- Device placement for Variables
- Sessions and Servers
- Fault tolerance
Model Replication
TensorFlow Graph is made of Variables and Operations. We assign them to device by the function with tf.device. Considering that we have a computer with 2 components /cpu:0 and /gpu:0, we could assign the variables to the /cpu:0 and the operations to the /gpu:0 with this:
with tf.device('/cpu:0'):
W = tf.Variable(...)
b = tf.Variable(...)
with tf.device('/gpu:0'):
output = tf.matmul(input, W) + b
loss = f(output)
If we don’t specify the device, TensorFlow will automatically choose the more optimal device, in this case, /gpu:0, to place both the variables and the operations.
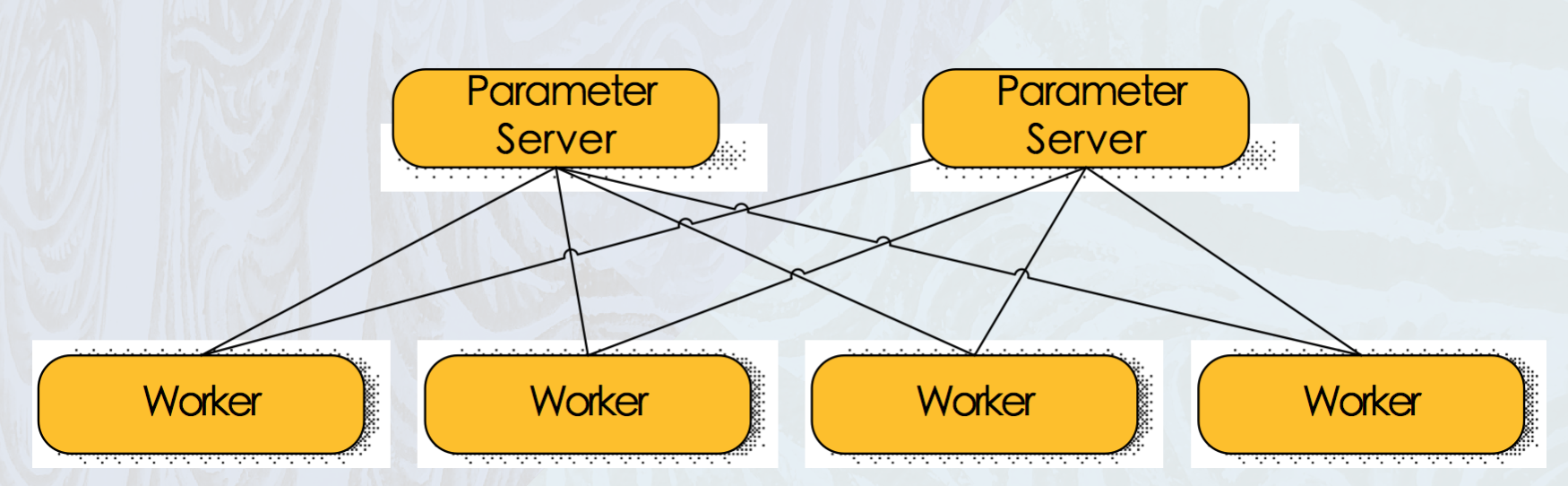
In TensorFlow, there are 2 jobs: parameter server (ps) and worker:
{kind=link}
Parameter server is responsible for storing the variables and updating the weights using the gradient from the worker. Correspondingly, the worker will compute the gradient and push it to the parameter server. In practice, ps job will be done by CPUs, while GPUs will act as worker thanks to their powerful parallel computing.
This mechanism inherits from the system called DisBelief. DisBelief has several limitations like difficult configuration (there are separated code for ps and worker, etc.) and its inability to share code externally. TensorFlow helps to simplify the configuration: ps and worker will run the almost the same code with a little modification.
In Data Parallelism, we will assign the model to every worker in the network. So the question is, how to replicate the model in every worker? There are two strategies for the model replication: In-Graph Replication and Between-Graph Replication.
In-Graph Replication
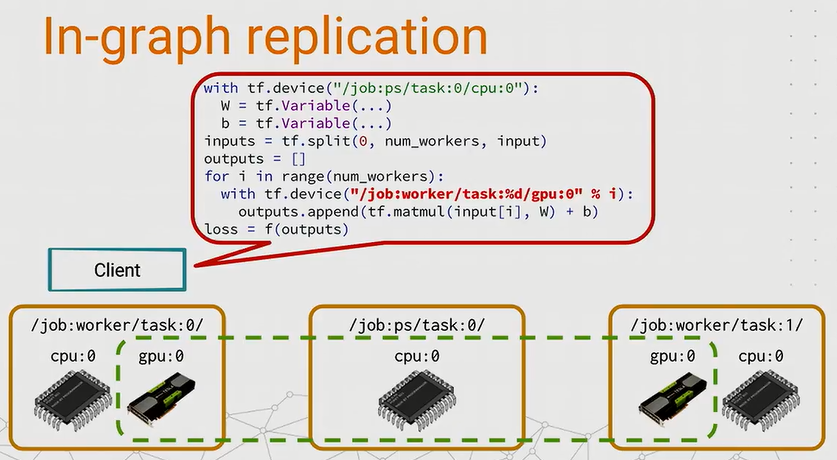
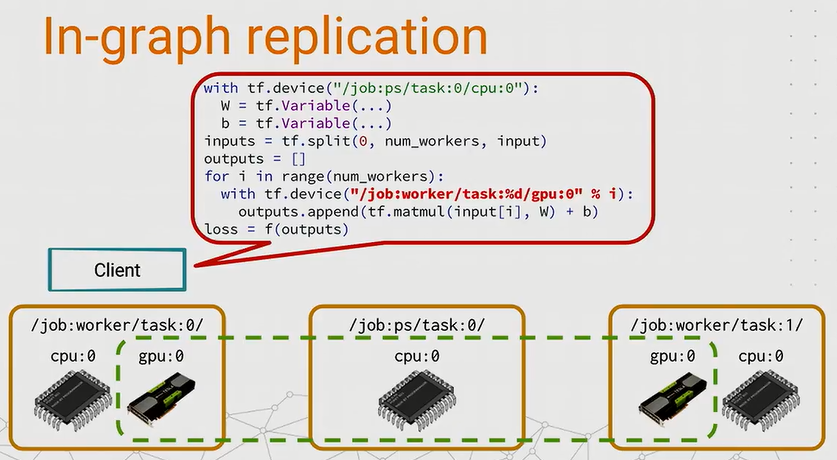
The client builds a single graph tf.Graph() which contains the parameters pinned to ps and the compute-intensive part (feed-forward operations and theirs back-propagation), each pinned to different tasks in the workers. This setting is not compatible with Model Parallelism.
{kind=link}
It is the most simple setting for replication, e.g, we don’t have to modify the code too much and it works well with simple architectures. However, when things get complicated, the tf.Graph() becomes bigger, it is not optimal that we assign the huge graph to every node in the network.
Between-Graph Replication
Each worker will build its own graph based on its responsibility. Generally speaking, each worker only shares the global variables placed on ps with each other and keep the local tasks for themselves. It is compatible with both Model Parallelism and surprisingly, Data Parallelism. In Data Parallelism, there will be a chief worker. Besides computing the gradient, the chief worker has to do some works like executing the tf.train.Saver() or logging, etc.
So the tf.Graph()s of the workers are not exactly the same.
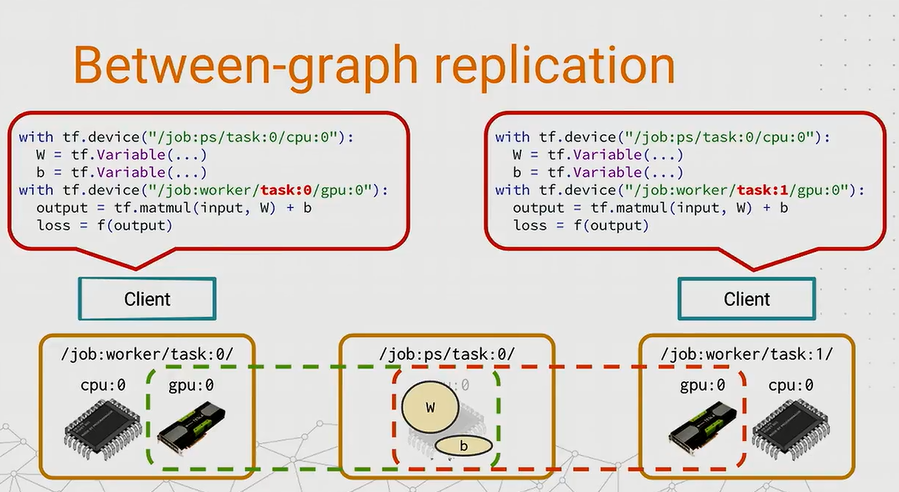
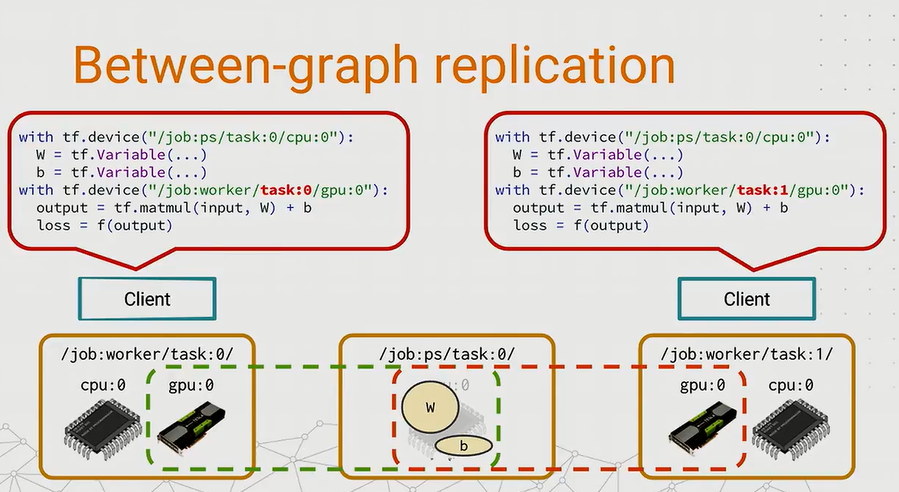{kind=link}
Nowadays, Between-Graph Replication overwhelms In-Graph Replication in Distributed TensorFlow thanks to its flexibility. In fact, it is difficult to find an example of In-Graph Replication.
A piece of code of Synchronous Between-Graph from our engine:
with tf.device(dev):
self.global_step = tf.train.get_or_create_global_step()
input_tensor = self.app.create_input_tensor()
input_tensor = [t for t in input_tensor]
input_tensor.append(self.global_step)
self.model_inst = self.model_cls(
input_tensor,
self.config,
devs=self.devs)
self.global_step = tf.contrib.framework.get_or_create_global_step()
self.lrn_rate = tf.train.exponential_decay(
self.train_cfg['init_lrn_rate'],
self.global_step,
self.train_cfg['step_change_lrn_rate'],
self.train_cfg['decay_lrn_ratio'],
staircase=True)
optimizer = select_optimizer(self.train_cfg['optimizer'],
self.lrn_rate, user_defined_optimizer)
exp_moving_averager = tf.train.ExponentialMovingAverage(
0.9, self.global_step)
variables_to_average = (
tf.trainable_variables() + tf.moving_average_variables())
self.sync_optimzier \
= tf.train.SyncReplicasOptimizer(
optimizer,
replicas_to_aggregate=replicas_to_aggregate,
total_num_replicas=num_workers,
variable_averages=exp_moving_averager,
variables_to_average=variables_to_average
)
self.model_inst.build_graph()
self.total_cost = self.get_total_loss()
if is_chief:
self.loss_averages_op = self.build_losses_avg_op()
cost_vars_map = self.model_inst.build_loss_vars_map()
grads = []
for map in cost_vars_map:
cost, vars = map
partial_grads = self.sync_optimzier.compute_gradients(cost, var_list=vars)
grads += partial_grads
if self.train_cfg.has_key('clipper') and self.train_cfg['clipper']:
clipper = select_clipper(clipper_info=self.train_cfg['clipper'],
user_defined_clipper=user_defined_clipper)
for grad, var in grads:
grads = [(clipper(grad), var)]
# build train op
apply_gradient_op = self.sync_optimzier.apply_gradients(
grads,
global_step=self.global_step
)
Device placement for Variables
When scaling up the distributed model, it is usually not sufficient to have only one ps in the network. Obviously, we could create several ps with different task_index and then assign the variables to these ps using with tf.device. But this manual assignment seems really dull when we have about 100 ps. TensorFlow tackles this issue by creating a function called tf.train.replica_device_setter(). This function outputs an instance which acts as the input of tf.device(). This function will distribute the variables among the ps tasks in round-robin style.

{kind=link}
Round-robin is the default strategy for variables placement. We could change this strategy by add value to ps_strategy, A more intelligent strategy worth considering is tf.contrib.training.GreedyLoadBalancingStrategy.

{kind=link}
Session and Server
In basic TensorFlow program, we often use tf.Session() to run the operations. But this function only know about the local machine. So there is a scenery that workers from different machines run independently if we keep everything unchanged. In Distributed TensorFlow, we invent two classes:
tf.train.ClusterSpec() and tf.train.Server to link the task in each machine together.
tf.train.ClusterSpec() specifies the machines which you want to run on and their job names. tf.train.Server() represents the task_index of each component in the cluster. In my opinion, each CPU/GPU will do a task and task_index helps to clarify chief_worker. Then we can pass tf.train.Server().target to tf.Session(). With that tf.Session()
could run code from anywhere in the cluster.

{kind=link}
For ps, it is much simpler. If this component is ps, it only has to run tf.train.Server().join() to combine the gradients from the workers.
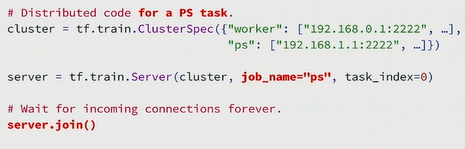
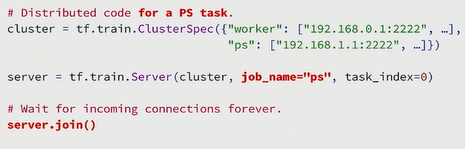{kind=link}
Fault Tolerance
A distributed system is a system in which I can’t get my work done because a computer has failed that I’ve never even heard of - Leslie Lamport
In any training system, there will be always a risk that training is interrupted because of machine corruption. In Distributed Training, the risk is multiplied by the number of component in the network. So we must have some measures to limit the risk.
tf.train.Saver()
We use tf.train.Saver() also in regular training, however, there are some things that we want to highlight in Distributed Training:
-
shardedif set to True will allows to write the checkpoints inpsin parallel instead of centralizing in oneps. It is recommended to set to True. -
As I have indicated above, only
chief workerhas the right to write the checkpoints, not to mention parameters initialization or summary recording. -
It is also able to write and send the checkpoint to cloud service instead of local machine to avoid the risk of machine corruption.
Scenarios
What if we encountered a problem during Distributed Training, how to recover from it? There are 3 possible scenarios:
-
Non-chief worker fails: it is the less severe case since it is stateless. When it is fixed, it just has to reconnect to
psto keep computing. -
Parameter server fails: it is more complicated since all the workers rely on it to compute and update the parameters. So when the
pscrashes, thechief workernotices its failure, stops the training of other workers and restores the system back to the last checkpoint. -
Chief worker fails: it is the most trickiest since
chief workerplays many roles in training. When it crashes, the training could continues, but since that moment, we lose control of the training. So in this case, everything will be stopped and we turn back to the last checkpoint, just like thepscase. To reduce the risk, we may exchange the role ofchief workerafter a number of steps.
tf.train.MonitoredTrainingSession()
It is really a wrapper of tf.Session(), especially useful for Distributed Training. It helps to initialize parameters without tf.global_variables_initializer, decide chief worker, do some additional work with hooks etc.

{kind=link}
A piece of code from our engine:
with tf.train.MonitoredTrainingSession(
master=self.server.target,
hooks=hooks,
chief_only_hooks=chief_only_hooks,
save_summaries_steps=0,
is_chief=is_chief,
config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=self.train_cfg['log_device_placement'])) \
as mon_sess:
if self.train_cfg['restore_sess'] and is_chief:
print("Restoring saved session...")
self._restore_session(restoring_saver, mon_sess,
self.train_cfg['restore_checkpoint_path'], cpkt_dir)
if hasattr(self.app,'session_start_callback'):
self.app.session_start_callback(mon_sess, model)
print("Run training operators...")
dataset_loading_time = self.train_cfg.get('dataset_loading_time', 3)
print("Delay %ds for starting queue runners." % dataset_loading_time)
time.sleep(dataset_loading_time)
while not mon_sess.should_stop():
mon_sess.run(train_op)
III. Conclusion
From our point of view, Distributed TensorFlow is the best distributed system for Deep Learning. At the moment, it is still improved by Deep Learning community to achieve better performance and to be more robust. In the next blogs, we may talk about deploying and serving on AWS by using Chef and Kubernetes.
IV. References
- Distributed TensorFlow
- https://www.oreilly.com/ideas/distributed-tensorflow(I don’t agree with the definition of Model Replication in this article, otherwise it is worth reading)
- DISTRIBUTED TENSORFLOW EXAMPLE
- http://lynnapan.github.io/2017/09/04/distributed%20tensorflow/#In-graph-replication