In the process of building news distribution platform for 24h News, we realize the importance of a Named-entity Recognition (NER) Model. It helps us to identify the user’s preferences, then we could amplify the effectiveness of the platform. In this blog, we will explain our approach in more details.
I. Bidirectional LSTM-CRF Models
First of all, I will describe briefly two most components of this model: Long Short Term Memory (LSTM) and Conditional Random Field(CRF).
a) LSTM
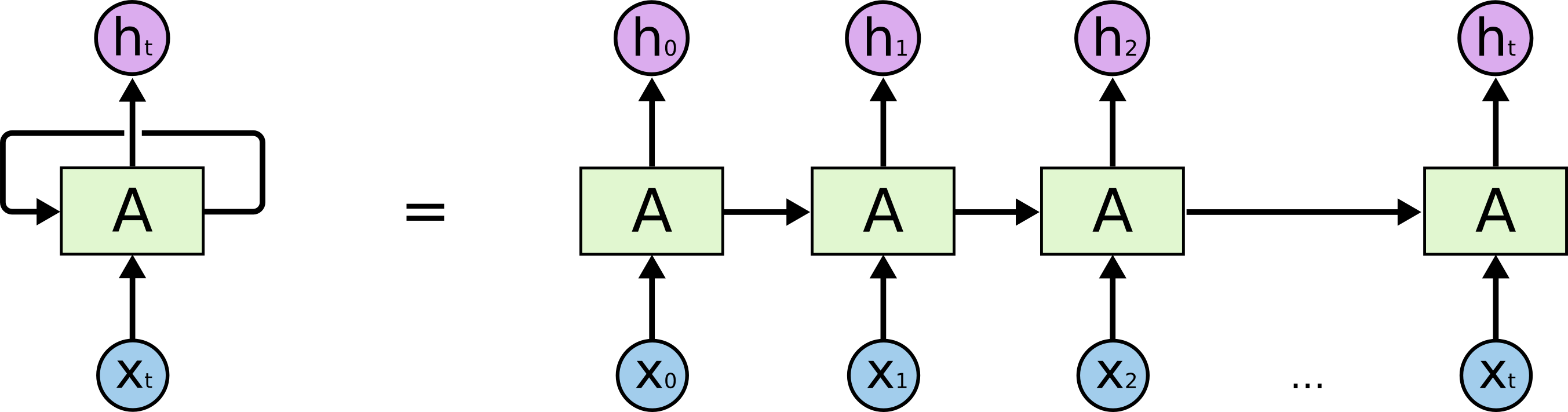
LSTM, in fact, is an variant of famous model for sequential data: Recurrent Neural Network. RNN solves the problem of sequential data by reasoning the previous events in the sequence to predict the current event.
{kind=link}
As you can see, apart from the inputs themselves, the model also use the previous output to predict the current one.
However, there is a problems with RNN: Its memory seems limited: It means that in some cases, we cannot retrieve the key information from the past since it is far from the current one. So we need to augment the memory of the model in order to connect two events between which there is a big gap.
Then LSTM is born! LSTM has its mechanism to filter unnecessary information and keep the important features. Therefore, we can extend the memory of the model in some meaning.
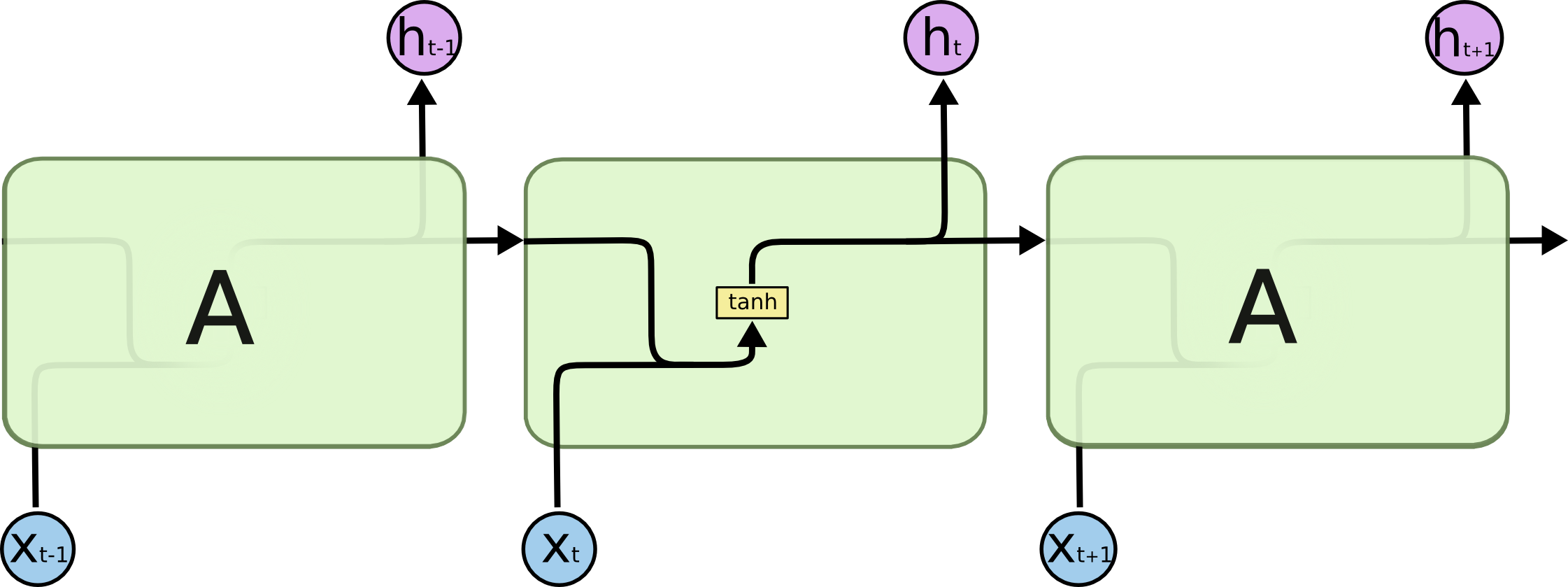
{kind=link}
In TensorFlow, we can use class tf.nn.rnn_cell.LSTMCell to implement LSTM Model.
An important extension of LSTM is Bi-LSTM. LSTM only uses the information for the past for the prediction. Bi-LSTM pushes it to limit by using two LSTM model to exploit both the past and future information.
b) CRF
Unlike LSTM, CRF is not an Deep Learning architecture but a Machine Learning method to deal with sequential data. CRF is a conditional form of the famous Hidden Markov Model for sequences. In HMM, we assume that there is a latent variable Y which affects the output X, so we need to maximize the generative probability P(X, Y) for the prediction. In CRF, we maximize the discriminative probability P(X|Y).
c) A fusion between BiLSTM and CRF
To amplify the ability to connect two entities in the corpus, we combine BiLSTM and CRF in a network. BiLSTM plays the role of feature engineering while CRF is the last layer to make the prediction.
class BiLSTM(object):
def __init__(self, num_tag_classes,
vocab_size, embedding_size=50,
n_hidden_gate=50, dropout_rate=0.0):
self.num_tag_classes = num_tag_classes
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.n_hidden_gate = n_hidden_gate
self.dropout_rate = dropout_rate
def __call__(self, x, seqlen, is_training=True):
with tf.variable_scope('embedding'):
embed_word = tf.contrib.layers.embed_sequence(
x, self.vocab_size, self.embedding_size,
initializer=tf.random_normal_initializer(0, 0.01)
)
print(embed_word.get_shape())
with tf.variable_scope('bi-lstm'):
# This version of LSTM is more advanced
tmp_embedding = tf.transpose(embed_word, perm=[1, 0, 2]) # input for LSTMBlockFusedCell must be in shape [max_steps, batch_size, input_size]
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(self.n_hidden_gate)
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(self.n_hidden_gate) # Not sure if it is necessary
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw)
fw_output, _ = lstm_cell_fw(tmp_embedding, dtype=tf.float32, sequence_length=seqlen)
bw_output, _ = lstm_cell_bw(tmp_embedding, dtype=tf.float32, sequence_length=seqlen)
output = tf.concat(axis=-1, values=[fw_output, bw_output])
output = tf.transpose(output, perm=[1, 0, 2])
if self.dropout_rate > 0.0 and is_training:
output = tf.nn.dropout(output, 1.0 - self.dropout_rate)
logits = tf.layers.dense(output, self.num_tag_classes)
return logits
crf_params = tf.get_variable('crf_params',
[params['numClasses'], params['numClasses']], dtype=tf.float32)
pred_ids, _ = tf.contrib.crf.crf_decode(logits, crf_params, features['seqlen'])
Please note that we have to save crf_params in the model. It plays an important role during the prediction.
II. Bi-LSTM with slot tagging
In this architecture, we empower Bi-LSTM by adding a fully-connected layer followed by softmax layer. This architecture works pretty well with CoNLL2003, in fact, I still don’t understand why exists this tremendous superiority.
with tf.variable_scope('embedding'):
embed_chars = tf.contrib.layers.embed_sequence(
x, self.vocab_size, self.embedding_size,
initializer=tf.random_normal_initializer(0, 0.01)
)
with tf.variable_scope('bi-lstm'):
lstm_cell = tf.nn.rnn_cell.LSTMCell(self.n_hidden_gate, state_is_tuple=True)
(forward_outputs, backward_outputs), (_, _) = tf.nn.bidirectional_dynamic_rnn(
cell_fw=lstm_cell, cell_bw=lstm_cell, inputs=embed_chars,
sequence_length=seqlen, dtype=tf.float32
)
if self.dropout_prob > 0.0 and is_training:
forward_outputs = tf.nn.dropout(forward_outputs, 1 - self.dropout_prob)
backward_outputs = tf.nn.dropout(backward_outputs, 1 - self.dropout_prob)
# Output is a tensor with shape (batch_size, max_seq, vector_size)
batch_size = tf.shape(x)[0]
max_seq_len = tf.shape(x)[1]
# Gather indices to dynamic outputs
# indices = tf.range(0, batch_size)*tf.shape(x)[1] + (seqlen - 1)
lower_triangular_ones = tf.linalg.LinearOperatorLowerTriangular(
tf.ones([max_seq_len, max_seq_len], dtype=tf.float32)).to_dense()
seqlen_mask = tf.slice(
tf.gather(lower_triangular_ones, seqlen - 1),
[0, 0], [batch_size, max_seq_len])
forward_outputs = tf.reshape(forward_outputs, [-1, self.n_hidden_gate])
backward_outputs = tf.reshape(backward_outputs, [-1, self.n_hidden_gate])
# Caculating lost for slot tagging
with tf.variable_scope("slot_tagging"):
w_tag_f = tf.get_variable(
'w_tag_f', [self.n_hidden_gate, self.n_hidden_tag],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01)
)
w_tag_b = tf.get_variable(
'w_tag_b', [self.n_hidden_gate, self.n_hidden_tag],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01)
)
bias_tag = tf.get_variable(
'bias_tag_b', [self.n_hidden_tag],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01)
)
w_softmax_tag = tf.get_variable(
'w_softmax_tag', [self.n_hidden_tag, self.num_tag_classes],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01)
)
bias_softmax_tag = tf.get_variable(
'bias_softmax_tag', [self.num_tag_classes],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.01)
)
with tf.variable_scope("softmax"):
#seq_tag_mask for true intent
tag_seq_layer = tf.add(tf.matmul(forward_outputs, w_tag_f),
tf.matmul(backward_outputs, w_tag_b))
tag_seq_layer = tf.add(tag_seq_layer, bias_tag)
tag_pre_softmax = tf.add(
tf.matmul(tag_seq_layer, w_softmax_tag),
bias_softmax_tag)
prediction_tag_prob = tf.nn.softmax(tag_pre_softmax)
prediction_tag = tf.reshape(tf.argmax(prediction_tag_prob, axis=1), [batch_size,-1])
#prediction_tag_reshaped = tf.reshape(self.prediction_tag, [-1, self.input_info['num_tag_classes']])
reshaped_seqlen_mask = tf.reshape(seqlen_mask, [-1])
III. Conclusion
Both model are tested with our data from 24hNews and CoNLL2003. With CoNLL2003 dataset, Bi-LSTM-CRF achieves 84% on the test set while BiLSTM-Dense gets 97%. With 24hNews dataset, the number is 90% and 96% respectively.
Clearly, Slot tagging outperforms the CRF, which is not very intuitive to us. We guess that, BiLSTM and CRF are good at remembering the faraway themselves, so the overall result is not impressive in comparison to each of them. We should instead increase the computing capacity by adding dense layer. We will conduct more experiments to test this hypothesis.