Recently, I’ve taken part in a online course in order to augment my salary. It is about Big Data and Apache’s tools in this area. So I decide to write a series about this topic. This series will act as a summary for my learning and also help to enrich the content of this site. In this course, they teach us about doing machine learning at scale and the way deploying machine learning model into production environment. That sounds great, right? So let’s begin.
I. What is Big Data
Based on the definition of Apache Hadoop Tutorial:
Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hands database management tools or traditional data processing applications.
Traditionally, the type of data we can imagine is the Excel sheet with a load of number and we can use Excel or some similar application to process and exploit useful information from it. Of course, it is not easy for an amateur to deal with the formulas in Excel but at least it has its own format for us to consider.
Nowadays, everything you create while surfing the internet can be consider as data and since it is enormous, so we name it Big Data. That Big Data provides a shape of who you are, where you are, what you want, etc. to the companies so that they could use it for a better market strategy. A picture could tell us where you live, click stream in a e-commerce site could help us to predict what you want in the future, etc. Sometimes, with this data, they could understand you more than you do. I strongly recommend this book, it will help you to realize the power of Big Data in this age.
Back to the topic, there are five properties of Big Data that you should notice:
-
Volume: The amount of data is so huge that we could not store it and process it efficiently in the traditional system.
-
Variety: The types of data now are so various, from text to music, from video to even click-stream. Furthermore, for each type of data, we also have many kinds of format to store them. For example, mp3 and wav in music or .doc and .json for text.
-
Velocity: Data is generated at a massive rate. In the past, not many people could possess a digital device to create data, but now, there are everywhere. So traditional system cannot keep up with this paces of data generation.
-
Value: Since the data is everything and everywhere, we have to find a way to exploit its value or else, it is just a piece of crap. Traditional systems cannot deal with this because of their processing power limit.
-
Veracity: Data always contains noises, not everything they tell us is true. So how to deal with this inconsistency is also a big problems to solve.
An interesting analogy could give you a better understanding of the origin of Big Data.
Supposed you run a small restaurant in town. You hire only 2 chefs since it is just a small resto in a small town. The chefs could serve 4 dishes per hour and they are satisfied with that productivity. As time of the Internet comes, your restaurant grows and starts receiving online order.
Now there are about 20 orders per hour and sure the old 2 chefs cannot meet that demand. As the result, you have to hire more chefs.
But the problem doesn’t end here. If many chefs share the same cook-shelf, obviously there will be a bottleneck. Each chef will have to wait other chefs to finish their shopping spree. It is not optimal. So we have to buy more cook shelf too!!!



Furthermore, we also have to optimize the work flow in the restaurant. For example, we divide our chefs into two groups: one deals with the raw material, the other transforms the preprocessed material into completed dishes.
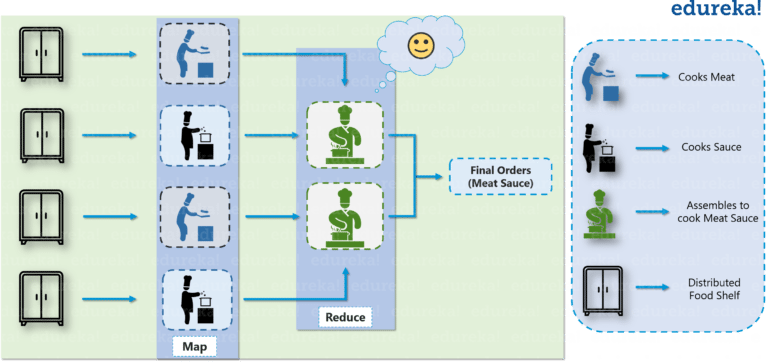
Similarly, when the data was in control, our traditional tools could handle it well. But when Digital Age comes, it brings multiple types of data with it, and it makes our tool useless. More specific, our old storage systems and processing units cannot cope with. We have to give them more power and more optimal mechanism so that our systems can work more efficiently. This is where Hadoop enters our life.
II. Hadoop Components
By definition:
Hadoop is a framework that allows us to store and process large data sets in parallel and distributed fashion.

Each system has its own components and its architecture to combine the components, Hadoop is not an exception. They are:
-
Hadoop Distributed File System
-
MapReduce
-
YARN
Both the components work in the master-slave fashion. Master is responsible for distributing the work load for each slave to to the job
1. Hadoop Distributed File System(HDFS)
In HDFS, we have two inferior components:
- NameNode:
- Maintain and manage DataNodes
- Record meta-data .i.e information about data blocks, size of the data
- Receive feedback and report from all the DataNodes
- DataNode:
- Store actual data
- Serve request from client
Normally, there are only one NameNode and many DataNodes. In case of one DataNode broken, we have back-up immediately. In addition, there is also a component named Secondary NameNode. You may guess it acts as a back-up for NameNode but it’s not. In fact, it plays the role in checkpoint process. In the Secondary NameNode, we combine periodically the entire history log and the most recent one into the only one, then it send the updated log file to NameNode for saving.
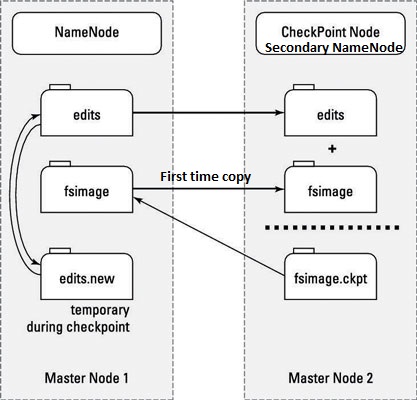
In general, when the client sends the data to the HDFS, the NameNode divides that data into smaller blocks and stores it in different DataNodes. Furthermore, for fault tolerance, each small blocks has its own replicas stored in different place.
Never put all eggs in one basket.
2. MapReduce
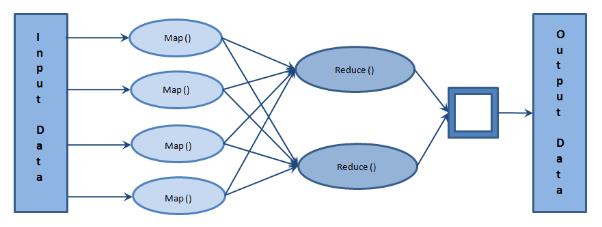
The principle of MapReduce is: Instead of letting one unit do all the work, we divide the work into simpler tasks, then distribute the tasks to many units to process in parallel (Map), then combine all the result to have the final output (Reduce)
3. YARN
Similarly to HDFS, YARN provides a distributed framework for processing. Different to other distributed solutions, we don’t bring the data to the processing unit, we install the processing unit in each DataNode. There are also two components:
-
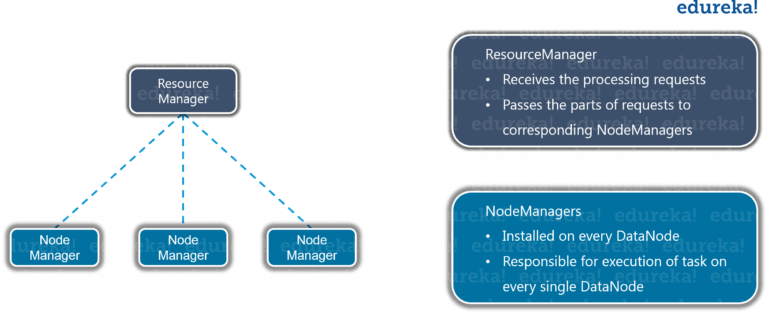
ResourceManager
- Receive requests from client.
- Pass request to corresponding processing unit.
- Supervise the work of each processing unit and combine the result from the slave machine.
-
NodeManager
- It resides in each DataNode
- Responsible for executing the task
- Communicate with the ResourceManager to remain up-to-date
III. Conclusion
Thanks to this architecture, Apache Hadoop brings to the users 4 benefits:

-
Reliability: we have a fault tolerance mechanism when things get broken. When one machine fails, there will be back-up machine available at the same time.
-
Economical: We could have many hardware configurations for the same task. It may help us to use the hardware more efficiently.
-
Scalability: Hadoop has very flexible mechanism in integrating new hardware, even the cloud service. So if you are able to install Hadoop on a cloud, you don’t have to worry about the scalability since the hardware is always available on the cloud service.
-
Flexibility: Hadoop can deal with all kinds of data, from structured, semi-structured to unstructured data.
This framework is so vast so that I cannot cover in a single blog. In the upcoming blogs, I will go in more detail about the MapReduce mechanism and other things.