In the previous post, I have presented an overview about Hadoop platform and its components. In this blog, I will dive more deeply into the storage system of Hadoop: HDFS architecture. Happy reading!!!
I. Background
As previously stated, HDFS has two elements: NameNode and DataNode. DataNode is responsible for processing and storing the data from the client. To efficiently organize the data, we create a NameNode for creating and storing metadata of the actual data: the location, the size, etc. Clearly, DataNodes in HDFS are organized in decentralized fashion, they resides in different racks, in different data centers. In order words, they expand in horizontal fashion.
Some words about HDFS. This platform is inspired by Google File System (GFS). While GFS is built in C++, HDFS is programmed in Java. Some key ideas in GFS are:
-
Platform failure is a norm, not an exception. So we have to prepare for plan B. All the data has its replicas.
-
Even space utilization: Each data has its own size, so we have to split the data to equal blocks to use the storage more efficiently.
-
Write-once-read-many: At a time, there is only one data writer but many readers. It helps to simplify the API and internal implementations of file system.
The reason that we decouple the HDFS into NameNode and DataNode is scalability. Metadata operations are fast, whereas data transfer last much longer. If they are combined as a single server, data transfer dominates metadata operation, which leads to the bottleneck in distributed environment.
How to read data in HDFS
Firstly, client requests NameNode to get data information, then establishes connection to DataNode to obtain blocks. These blocks are distributed in different machines, but you don’t have to worry about this complexity. It is total transparent to users. What you see is the data stream from DataNode. If at some points in the future, a DataNode is corrupted, HDFS will retrieve the replica from another DataNode automatically for you. Furthermore, it will choose the replica in the nearest DataNode for you, both in physical aspect or logical aspect when there is a system overload at a DataNode. Pretty convenient, right?
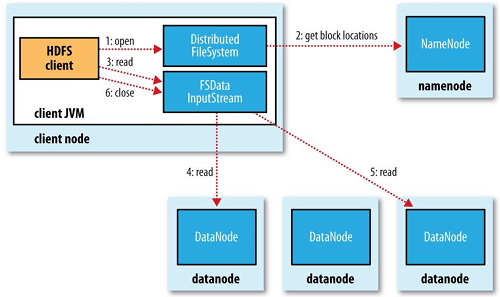
As you can see, there are many readers working at the same time.
How to write data in HDFS
As I have mentioned above, each file will split into different blocks, and each blocks has its own replicas. Hadoop distributes these replicas in different places: the first DataNode is chosen randomly, the second will be in a different rack and the third may be in a different machine in the same rack with the second. This arrangement will help us to economize the cost of distribution and data retrieve.
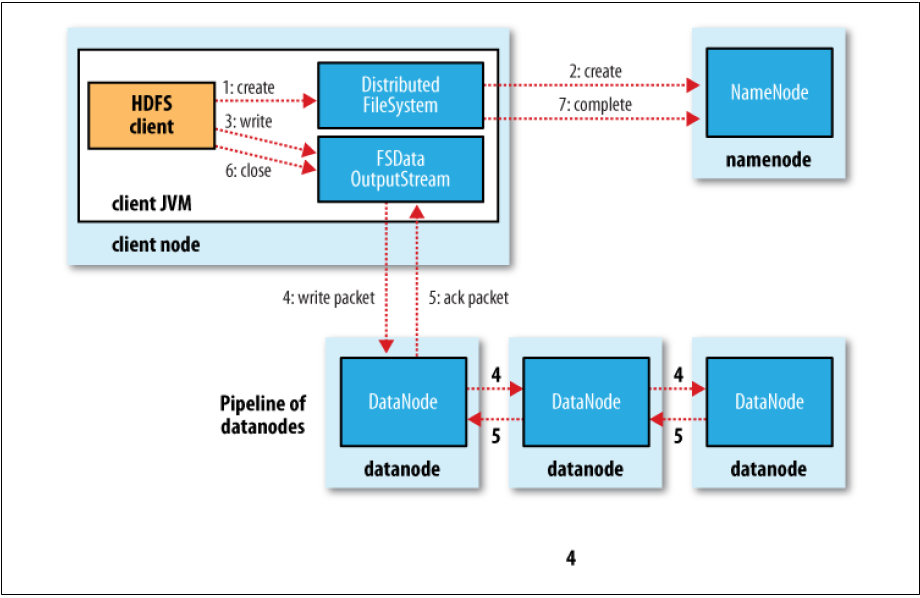
Here is the process:
-
The client requests the NameNode for the permission to write data. The NameNode checks the validity and possible conflicts. If nothing is wrong, the client is authorized to write data, called lease.
-
The client asks for a list of DataNodes. These DataNodes then form a pipeline.
-
The client then sends the data packet to the nearest DataNode. This DataNode becomes Primary DataNode(PD) and be responsible for distributing the replica to other DataNodes. If nothing goes south, it will respond the acknowledgment to the client. Or else, PD will close the pipeline and ask for replacement of DataNode, then continue the work.
II. Node Architecture
a) DataNode
As mentioned above, DataNode contains a collection of data block of a specific size. In Hadoop 1.0 and 2.0, the default block size is 64MB and 128MB, respectively. In this blog, I assume the default block size is 128MB. This is how the DataNode is organized. The actual data for DataNode is replica, please don’t mistake this point. Logically, each replica whose size lower than 128MB will occupy a whole block, if it is larger, it will start evade another block and so on. But you don’t have to worry about the memory waste if the file is just 1MB. Physically, it just occupies the same space as its size in the disk like other ordinary file systems. This abstraction will bring the benefit of uniform data distribution, it is efficient to any files, small or large.
Have you ever wondered why the default value is 128MB and 64MB in the past? You cannot choose the block too small. Firstly, it will lead to the over-population of metadata in NameNode. Secondly, if we divide a large file into too many small blocks, it takes us many requests to get the entire data when needed. Thirdly, increasing the data block will help to alleviate the cost of data seeking by augmenting the time for transfer. In reverse, we have to keep the size not so large to exploit the parallelism to its best.
It is the principles. But why choosing 64MB and then 128MB? The objective is keep the seeking time is just 1% of data transfer time. The seeking time is relatively constant while the transfer time accelerates day after day. In the past, 64MB is enough to keep that ratio, but now it must be about 128MB.
b) NameNode
NameNode contains metadata of the actual data block in DataNode(not replica). Each file to be written to DataNode requires two types of object in NameNode: one inode file and \(n\) blocks, \(n\) is the number of blocks that file will be divided into. Each above object will take 150KB, this number is constant, no matter what size of the actual data. So as you can see, if you split the file too tiny, it is very wasteful and we refer it as small file problems.
Most of the time, metadata operations stay in RAM area for the sake of speed, but its backup stay in a hard drive.
For instance, a file of 192MB will occupy 2 blocks(128MB + 64MB), so the metadata of this file will cover 450KB of RAM (1 inode file + 2 blocks). 192TB of this kind will cover 450MB. This number is independent of the replication factor. The bigger the replication factor, the more disk capacity in DataNode we need but the memory usage stays the same.
Example: Estimating the memory used
A, B, C have the same amount of data but they split the data into different file sizes
-
A: 1 x 1024MB
- 1 inode file
- 8 blocks (1024/128)
\(\rightarrow\) Total memory usage: 9 * 150 = 1350B
-
B: 8 x 128MB
- 8 inode file
- 8 blocks
\(\rightarrow\) Total memory usage 16 * 150 = 2400B
-
C: 1024 x 1MB
- 1024 inode file
- 1024 blocks
\(\rightarrow\) Total memory usage 2048 * 150 = 307200
Which kinds of metadata does NameNode contains? It maintains a list of registered DataNodes and their inferior blocks. It includes data location, permission details and date of creation. To update this list, it receives a block report from the NameNode periodically including block ID, length, generation stamp(it indicates somehow the state of replicas).
Furthermore, to update the state of DataNode, NameNode has to receive a signal called heartbeat. If it receives nothing in a period, NameNode will alert the system that DataNode is dead and prepare for the replacement.