In the previous post, I have finished presenting the architecture of HDFS. Today, I focus more on the fault tolerance, in other words, the recovery process of HDFS. As you may know, HDFS developers assume that this platform will run on the unstable system. fault tolerance can’t be ignored if you want to master Hadoop system.
I. States and transition
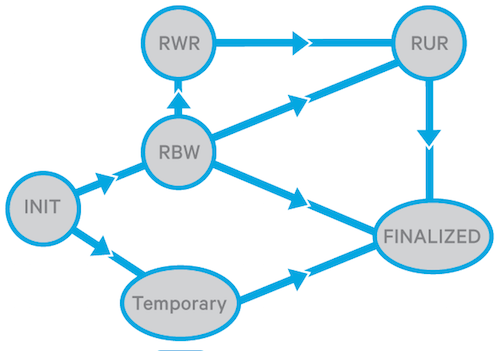
1. States and transitions of Replica in DataNode
-
Finalized: This is the cool-and-dry state of replica. In other words, replicas take this title when everything is perfect, every replica of a data block have a full content and acquires a same generation stamp. Generation stamp is a code which somehow describes the version of a replica, it only changes when a replica is created or appended. At this state, corresponding metadata in NameNode is aligned with the replica’s state and data.
-
Replica Being Written(RBW): This is the state of currently written part of file. During this state, replica is a little messy: metadata may not match the replica. In case of failure, HDFS will try to preserve as many bytes as possible: it is called as data durability.
-
Replica Waiting to be Recovered(RWR): If RBW goes south, the replica will turn to this state. This data will be either discarded or recovered in lease recovery if client dies.
-
Replica Under Recovery(RUR): This is the state of replica during lease recovery.
-
Temporary: This happens when data distribution in different nodes is not uniform. In this case, we either do data re-balancing takes place or increase the replication factor. It is totally transparent to the user.
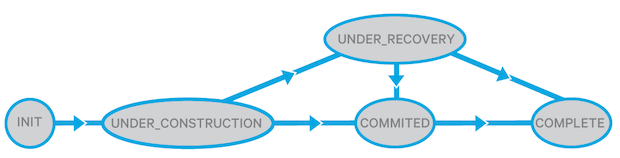
2. States and transitions of Block in NameNode
In the previous post, I have mentioned that each data block (not replica) to be written to DataNode have its own block in NameNode. These block have its own states and transition mechanism.
-
Under Construction: This is the block state when the corresponding data block is being written. It is used to keep track of the write pipeline, especially the RBW and RWR replicas.
-
Under Recovery: When the lease of a client expires or the client dies, the corresponding block in NameNode will turn to this state.
-
Committed: This is when the client successfully sends all the content. It has to keep track all RBW state in DataNode. Notice that this is not the end. Remember that the client only writes the data directly to the PD. Then the remaining replicas will be processed automatically inside NameNodes.
-
Complete: It is when all the replicas are in finalized state.
II. Recovery Process
There are 3 types of recovery in HDFS:
-
Block recovery
-
Lease recovery
-
Pipeline recovery
Block Recovery
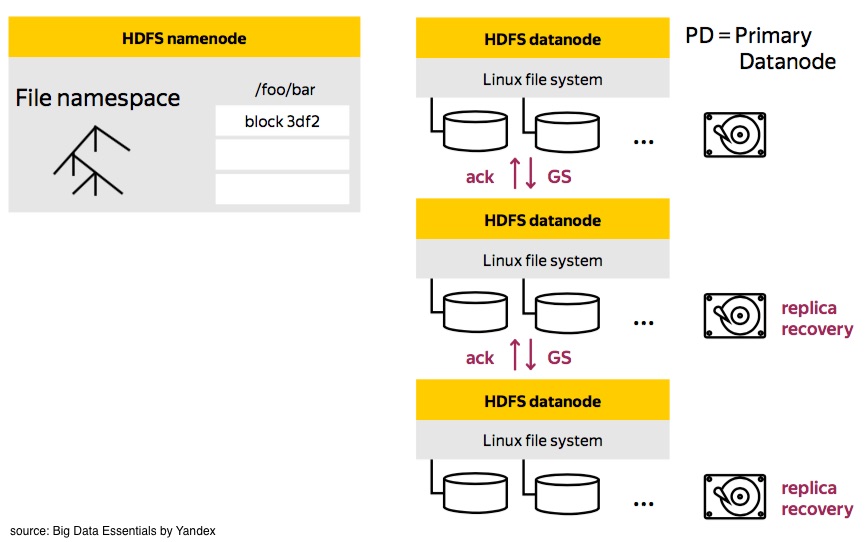
In case of block writing failure, the last block being written is not propagated to all the DataNodes, the data blocks in DataNode needs recovering. Hope you remember that there is a Primary DataNode which receives data directly from client. In this recovery, NameNode also chooses a Primary DataNode(PD), PD will be responsible for this process:
-
PD asks for generation stamp and location of other DataNodes from NameNode.
-
PD contacts other DataNode for recovery process. During this time, DataNodes abort access from clients and reach agreement about the content of data block after recovery. Then all the necessary data will be transferred through pipeline
-
PD will report the result to the NameNode: successful and failed. We may re-recover the whole process if necessary.
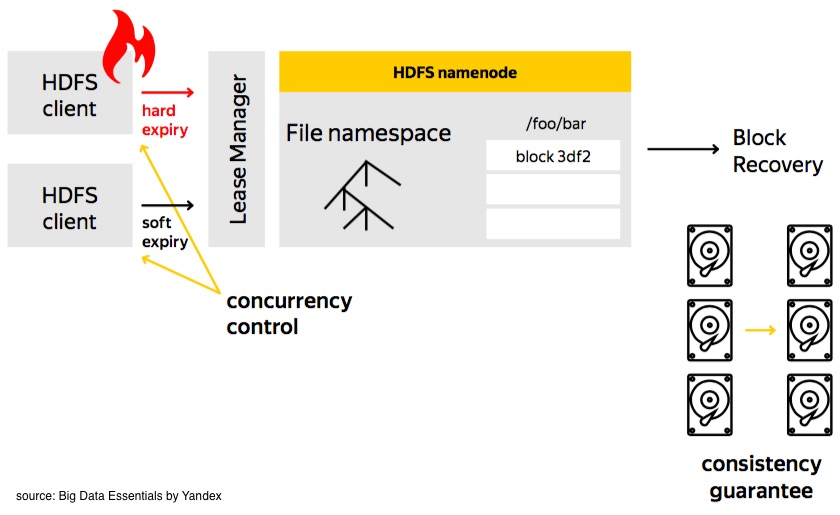
Lease Recovery
To have a right to write an HDFS file, it must obtain a lease, which is a guarantee that only one writer can work at a time. This lease must be renewed continuously for a writer to keep writing. If the lease is expired, HDFS will close the file and take back the lease of that client, then we may exercise the block recovery if necessary.
You have to notice that there are 2 limits in this lease recovery: soft limit and hard limit. Before the soft limit expires, the client has exclusive access to the file. Between the soft limit and hard limit, another client can forcibly take the lease. After the hard limit, HDFS assumes that client has quit, therefore recovers the lease.
For this process, there will be a Lease Manager to manage the whole thing. Throughout the whole process, we achieve two guarantees:
-
Concurrency control: After the hard limit, even the client is alive, it won’t be able to write data.
-
Consistency control: After the recovery, all the replicas roll back to the same version.
Pipeline Recovery
For the ones who have background in telecommunication, this graph below must be familiar:
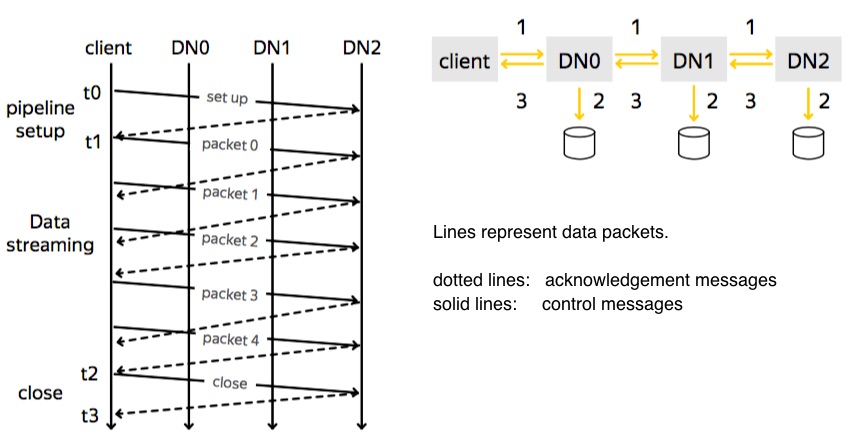
There are 3 phases for writing data:
-
Pipeline setup: Client connects to the DataNodes and receives ack package from them.
-
Data streaming: Data block is divided into packets and these packets will go through the pipeline to be written in the DataNodes.
-
Close: This is when finalizing the replicas.
There are 3 corresponding schemes:
- Setup failure:
- If the pipeline is created for a new block, the client abandons that block and asks the NameNode for a new block and new list of DataNodes. Then it restarts the pipeline.
- In case of block appending, the client rebuilds the pipeline with the good DataNodes and increments the GS
- Streaming failure:
- If DataNode detects an error, it retreats itself from the pipeline by closing all the TCP/IP connections.
- If the client detects an error, it stops sending data and reconstructs the new pipeline.
- The client resumes sending data. It checks which packets have been received successfully and continues sending the remaining ones.
- Close failure:
- It rebuilds the pipeline and finalized the remaining replicas which is not finalized.
III. Conclusion
Block recovery, lease recovery and pipeline recovery are the three main pillars of fault tolerance in HDFS. They work transparently to us and help us to deal with inconsistency of the Big Data world. Hope the blog gives you a initial idea how HDFS achieves that robustness and consistency during its activities with unstable hardware. If you notice something wrong with the content, please comment below. At the end, we are all learners :)