In the re:Invent2018, CEO of Amazon Web Service has introduced Amazon Personalize, a service which helps customers to initialize their own Recommend System (RecSys) without expertise. I am quite surprised that they haven’t launched this service earlier when recommendation is really their strong point. I am assigned a task to research about this service and I will cover about it in this blog.
I. What is Amazon Personalize
Amazon Personalize is a framework which helps us to build a proper RecSys. It includes how to build dataset, how to choose appropriate algorithms and hyperparamters and how to deploy it into production. Previously, AWS has introduced Amazon Sagemaker for machine learning, and surely it can be used for recommendation but Personalize focuses entirely on the branch. You don’t have to understand much about machine learning to use this efficiently. This service will cover four minor applications: music recommendation, product recommendation, film recommendation and article recommendation.
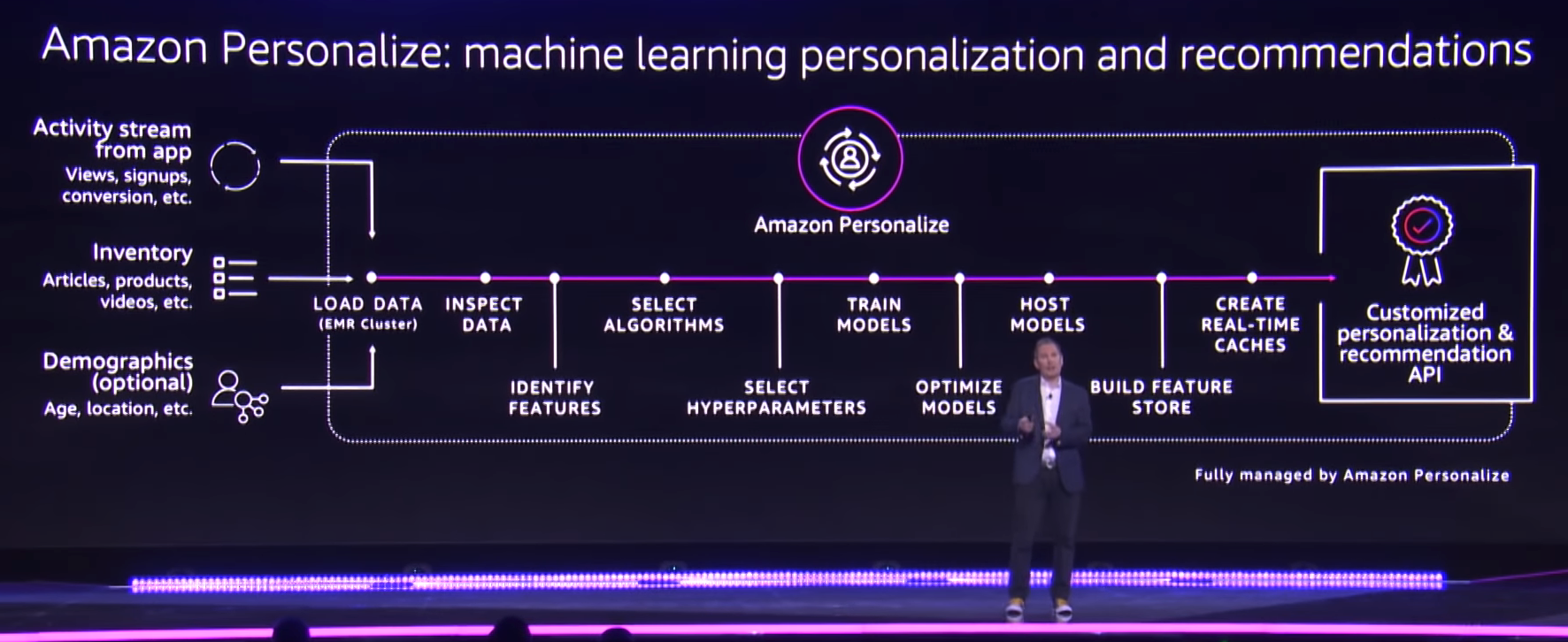
In general, Amazon will do all the stuffs for you: collecting data, training model and deploying model. There are 3 main components correspondingly:
-
Amazon Personalize: Use this to create, manage and deploy solutions.
-
Amazon Personalize Events: Use this to record users event for further training.
-
Amazon Personalize Runtime: Use this to get the recommendation from campaign.
There are several concepts that you need to understand before diving into this service:
-
Dataset: Obviously, you need data to train your model. Outside dataset has to come with a schema for it to be defined in Personalize. There are three type of dataset in Personalize: Users, Items and Interactions. Each type will have its own schema that you must follow
-
Dataset group: Training a model requires you to define a dataset group which is a collection of dataset. Each dataset group may have several types of dataset so that the service has more information to decide the algorithms
-
Recipe: it is the algorithm in Amazon Personalize. Up to now, there are 6 different built-in algorithms for you to choose. Otherwise, you could create your own algorithm.
-
Solution: it is the model after training. It is the precious child of dataset group and recipe.
-
Metrics: it is the tool which helps you evaluate your solution after training.
-
Campaign: the hosting service that your solution resides. Each time you need the real-time recommendation, you need to call the campaign on the fly via endpoint.
-
Recommendation: the result of the whole process you have been doing.
And what is the workflow of Amazon Personalize?
- Create a dataset group
- Import your data into dataset group
- Create solution using recipe and dataset.
- Evaluate solution thanks to metrics and tune the hyperparameters
- Create a campaign (deployed solution)
- Provide recommendations for user
- Continue improve the trained model based on user activities

There are three main ways to access Personalize: Personalize console, AWS CLI and AWS SDK (boto3). In this blog, everything will be presented with boto3 in Python.
II. Recipes in Personalize
As stated above, there are 6 built-in algorithms built by Amazon for you to choose. In this section, since the document on the website is incomplete, I will cover their usages based on my knowledge, feel free to correct me if you think my understanding is erroneous.
-
DeepFM: Matrix factorization is so popular in RecSys world. It is used to analyze the interaction between users and items. In principle, each user interacts with some items but not all. So based on their interactions and the others interactions, we predict their preferences with other items. Previously, this task is done in the machine learning style, using SVD and other related algorithms. They just work for average customer and long-lived items. Now we could employ neural network to solve this problems more efficiently.
-
FFNN: I just know that FFNN stands for Fast Forward Neural Network, but how does it work or what its applications are, I totally have no ideas since Amazon doesn’t present anything about it
-
HRNN: It stands for Hierarchical Recurrent Neural Network. HRNN system is employed to predict the user’s behavior changes with time. The more recent activities will have more weight than the old ones. The timestamp data will be incorporated into the system so that we could predict more accurately.
-
Popularity-baseline: It simply counts the most popular item in the dataset. It is usually considered as the baseline to compare other recipes.
-
Search Personalization: It is used to predict the user preferences: which one he likes the most ? etc.
-
SIMS: It is item-to-item similarity recipe. It is basically the collaborative filtering, and it also leverages the interactions between users and items to recommend the similar items to the users. In the absence of user-item interactions dataset, it is the most optimal recipe.
Other than built-in algorithm, if you want to tailor yourself a recipe, Personalize also supports that. You just have to dockerize your algorithm in SageMaker standard and store it in ECR.
III. Example
In this part, I will cover an example with Movielens dataset with Python SDK. Movielens is a huge dataset of user-item interactions in film industry. It has 4 columns: User_ID, Item_ID, Rating and Timestamp
- First of all, we have to prepare the environment:
import boto3
import json
import numpy as np
import pandas as pd
import time
!wget -N https://s3-us-west-2.amazonaws.com/personalize-cli-json-models/personalize.json
!wget -N https://s3-us-west-2.amazonaws.com/personalize-cli-json-models/personalize-runtime.json
!aws configure add-model --service-model file://`pwd`/personalize.json --service-name personalize
!aws configure add-model --service-model file://`pwd`/personalize-runtime.json --service-name personalize-runtime
personalize = boto3.client(service_name='personalize', endpoint_url='https://personalize.us-east-1.amazonaws.com')
personalize_runtime = boto3.client(service_name='personalize-runtime', endpoint_url='https://personalize-runtime.us-east-1.amazonaws.com')
- Prepare and upload data to S3
bucket = "personalize-demo" # replace with the name of your S3 bucket
filename = "DEMO-movie-lens-100k.csv"
!wget -N http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -o ml-100k.zip
data = pd.read_csv('./ml-100k/u.data', sep='\t', names=['USER_ID', 'ITEM_ID', 'RATING', 'TIMESTAMP'])
pd.set_option('display.max_rows', 5)
data = data[data['RATING'] > 3.6] # keep only movies rated 3.6 and above
data = data[['USER_ID', 'ITEM_ID', 'TIMESTAMP']] # select columns that match the columns in the schema below
data.to_csv(filename, index=False)
boto3.Session().resource('s3').Bucket(bucket).Object(filename).upload_file(filename)
Noted that you have to specify your key and secret key in the Session() in order to upload it successfully.
- Then define the schema for your data. The reason is EMR will play the role of pre-processing your data and DataFrame is its favorite data format. The schema must follow Avro format
schema = {
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
create_schema_response = personalize.create_schema(
name = "DEMO-schema",
schema = json.dumps(schema)
)
schema_arn = create_schema_response['schemaArn']
print json.dumps(create_schema_response, indent=2)
- Then create the dataset group
create_dataset_group_response = personalize.create_dataset_group(
name = "DEMO-dataset-group"
)
dataset_group_arn = create_dataset_group_response['datasetGroupArn']
print json.dumps(create_dataset_group_response, indent=2)
- The dataset group creation takes time so we have to wait for it.
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_dataset_group_response = personalize.describe_dataset_group(
datasetGroupArn = dataset_group_arn
)
status = describe_dataset_group_response["datasetGroup"]["status"]
print "DatasetGroup: {}".format(status)
if status == "ACTIVE" or status == "CREATE FAILED":
break
time.sleep(60)
- Create a Personalize dataset and import data from S3 to it
dataset_type = "INTERACTIONS"
create_dataset_response = personalize.create_dataset(
datasetType = dataset_type,
datasetGroupArn = dataset_group_arn,
schemaArn = schema_arn
)
dataset_arn = create_dataset_response['datasetArn']
print json.dumps(create_dataset_response, indent=2)
create_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "DEMO-dataset-import-job",
datasetArn = dataset_arn,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, filename)
},
roleArn = role_arn
)
dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']
print json.dumps(create_dataset_import_job_response, indent=2)
- The above step takes time too since we have to download data from S3
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_dataset_import_job_response = personalize.describe_dataset_import_job(
datasetImportJobArn = dataset_import_job_arn
)
dataset_import_job = describe_dataset_import_job_response["datasetImportJob"]
if "latestDatasetImportJobRun" not in dataset_import_job:
status = dataset_import_job["status"]
print "DatasetImportJob: {}".format(status)
else:
status = dataset_import_job["latestDatasetImportJobRun"]["status"]
print "LatestDatasetImportJobRun: {}".format(status)
if status == "ACTIVE" or status == "CREATE FAILED":
break
time.sleep(60)
- Choose recipe and train a solution
recipe_list = [
"arn:aws:personalize:::recipe/awspersonalizehrnnmodel",
"arn:aws:personalize:::recipe/awspersonalizedeepfmmodel",
"arn:aws:personalize:::recipe/awspersonalizesimsmodel",
"arn:aws:personalize:::recipe/awspersonalizeffnnmodel",
"arn:aws:personalize:::recipe/popularity-baseline"
]
recipe_arn = recipe_list[0]
create_solution_response = personalize.create_solution(
name = "DEMO-solution",
datasetGroupArn = dataset_group_arn,
recipeArn = recipe_arn,
minTPS = 1
)
solution_arn = create_solution_response['solutionArn']
print json.dumps(create_solution_response, indent=2)
- Wait for the training to complete
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_solution_response = personalize.describe_solution(
solutionArn = solution_arn
)
status = describe_solution_response["solution"]["status"]
print "Solution: {}".format(status)
if status == "ACTIVE" or status == "CREATE FAILED":
break
time.sleep(60)
- Evaluate the solution
get_metrics_response = personalize.get_metrics(
solutionArn = solution_arn
)
print json.dumps(get_metrics_response, indent=2)
- Create the campaign from the qualified solution
create_campaign_response = personalize.create_campaign(
name = "DEMO-campaign",
solutionArn = solution_arn,
updateMode = "MANUAL"
)
campaign_arn = create_campaign_response['campaignArn']
print json.dumps(create_campaign_response, indent=2)
Noted that updateMode equals ‘MANUAL’ means that we may have the more updated solution using more data but we have to update it in the campaign our-self. Surely, we can make it automatic by changing the value.
- Wait for the above step to complete
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_campaign_response = personalize.describe_campaign(
campaignArn = campaign_arn
)
status = describe_campaign_response["campaign"]["status"]
print "Campaign: {}".format(status)
if status == "ACTIVE" or status == "CREATE FAILED":
break
time.sleep(60)
- Get the recommendation
items = pd.read_csv('./ml-100k/u.item', sep='|', usecols=[0,1], header=None)
items.columns = ['ITEM_ID', 'TITLE']
user_id, item_id, _ = data.sample().values[0]
item_title = items.loc[items['ITEM_ID'] == item_id].values[0][-1]
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = campaign_arn,
userId = str(user_id),
itemId = str(item_id)
)
item_list = get_recommendations_response['itemList']
title_list = [items.loc[items['ITEM_ID'] == np.int(item['itemId'])].values[0][-1] for item in item_list]
print "Recommendations: {}".format(json.dumps(title_list, indent=2))
IV. Conclusion
This service, to me, is very promising since it is really the expertise of Amazon. However, it is still in development. By the time this blog is published, I still cannot get the authorization to try it and the document is still a mess. But hey, stay tuned for the upcoming news from Amazon.