Recently, I reluctantly had a task involving image segmentation. Why reluctance? As a deep learning engineer, I don’t really believe in the power of this branch since convolutional network doesn’t work well in pixel level (I think!!!). Anyways, I give it a try and now I want to share with you my (limited) knowledge about image segmentation, more specifically, real-time instance segmentation.
I. What is image segmentation?
You must be familiar with object detection, which outputs a bounding box and label for the object inside. There are 2 main types of object detection models: Two-stage detectors (like Fast RCNN, Faster RCNN, etc.) and one-stage ones (SSD, YOLO, etc.). Obviously, the former overpowers the latter in terms of accuracy due to its complicated design, while lagging behind in inference speed. Nevertheless, the gap in accuracy has been significantly filled thanks to the advent of smart-designed one-stage detection like YOLOv5 or DSOD.
As object detection becomes more and more matured, researchers over the world feel the need of more sophisticated representation rather than bounding boxes. That’s how image segmentation was created. This architecture aims to assign correctly every pixel in the picture to its entity. There are two branches of image segmentation: semantic segmentation and instance segmentation.
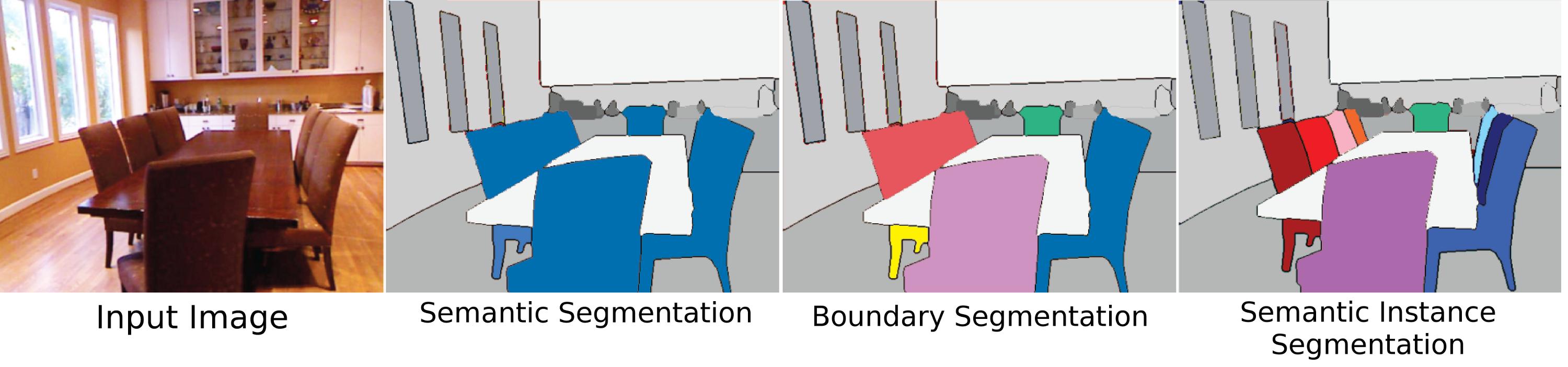
As can be seen easily, semantic segmentation is much simpler than instance segmentation. While semantic segmentation is simply a classic problem of classification of every pixel in the image, instance segmentation must differentiate correctly every entity of the same type. Basically, instance segmentation can be seen as object detection plus semantic segmentation.
Just as object detection, instance segmentation also has 2 types of architectures: one-stage and two-stage. Mask_RCNN, to my knowledge, is the best in terms of accuracy. However, I will mainly focus on one-stage segmenter, which is more useful in real life.
II. YOLACT
Original design of YOLACT bases on Feature Pyramid Network(FPN), a well-known multi-scale object detection architecture. It has two main differences:
-
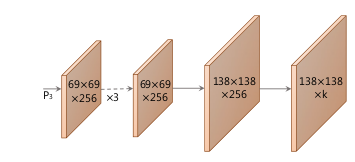
From layer
P3, it produces k prototype segmentation masks for theentire image. The use of prototypes will be explained below. -
Beside class and box prediction, the network also predict mask coefficients, each corresponds to a prototype.
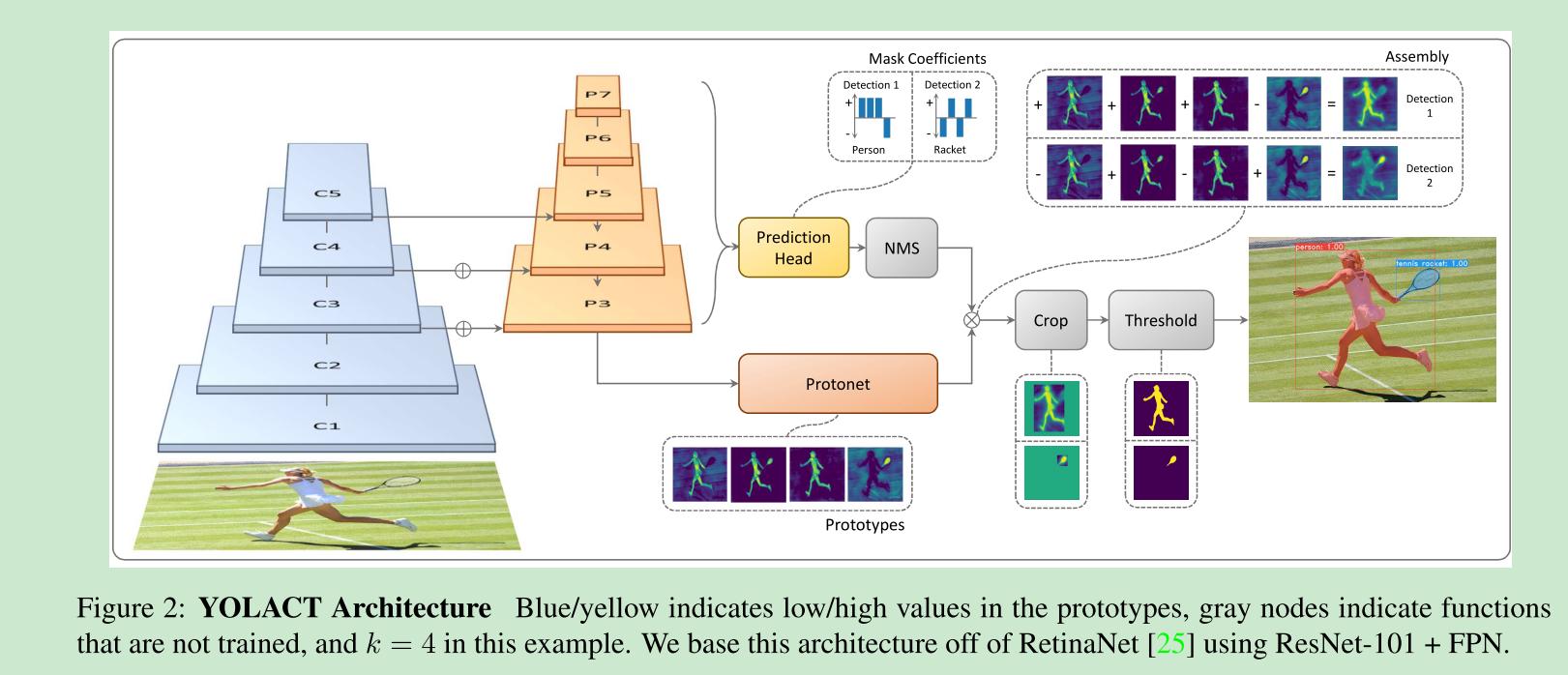
How does this architecture works?
As you can see, it provides additionally k prototypes and mask coefficients. These additional features helps to construct masks for each instance. In more detailed, along with bounding box and score, we will predict a k-sized vector. For each instance, we will compute sigmoid of linear combination of k prototypes and mask coefficients.
If you are training, you should crop the mask using ground-truth bounding box in order to compare with the ground-truth
mask when computing mask loss. During inference, bounding box produced by object detection branch is good enough.
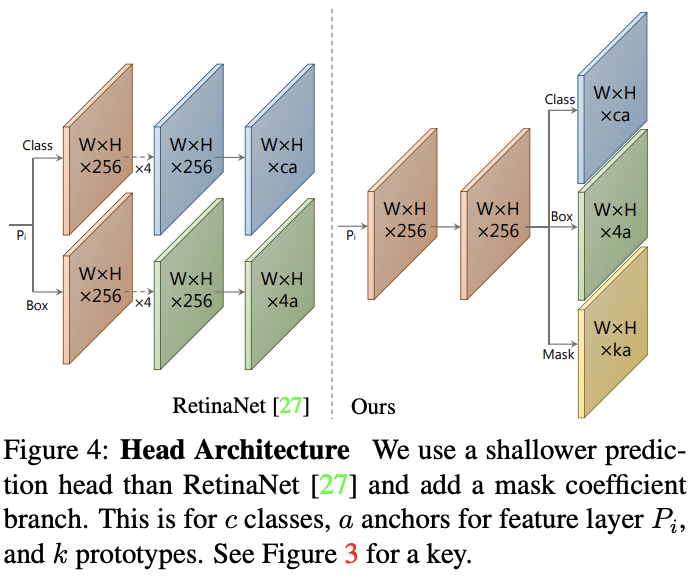
About loss computation, in the official implementation, like SSD, the authors use MultiBoxLoss to train detection branch. About mask branch, we use BCE Loss to train this subnet. As you can see,
we do not train protonet directly.
Another advantage of this design is that we could integrate it into any one-stage detection architecture. Therefore, we could rely on recent advance in this area in order to improve our segmenter in deployment. This also means that data preparation, including writing data loader, will be relatively simple.
Fast NMS
The authors of this work also propose a new way to accelerate NMS, which is traditionally performed sequentially
on CPU. More specifically, for each of c classes, we compute IoU matrix for top n detections by score. As a result,
we have c x n x n matrix and then, we could discard any detections which has corresponding IoU than a threshold t.
Undoubtedly, with this relaxation, we remove larger number of detected instance after NMS. However, it can be considered negligible, according to the figure in the paper.
YOLACT++
As you can see, there is a problem with this design: Segmentation branch depends heavily on the detection branch. This leads to 2 issues:
- We have a computation overhead when we need to execute detection branch even when this information is redundant.
- Since mask head and detection head are relatively independent, there may be the case when satisfactory mask representations are discarded because they don’t have class confidences score high enough to survive NMS stage.
To address the second issue or in another word, to better correlate the class confidence with mask quality, YOLACT++ introduce mask re-scoring branch based on their mask IoU with ground-truth. This sub-branch takes cropped mask prediction
and outputs mask IoU. The product of mask IoU and class confidence will be a coefficient to re-score mask prediction before computing loss. According to the paper, its computational overhead remains negligible while improving its accuracy
significantly.
In this version, they also employ Deformable Convolution Network because of `its replacement of the rigid sampling with free-form sampling. You could see the improvement in more detailed in the paper.
YOLACT Edge
Another variant of YOLACT that I would like to mention is Yolact Edge, a version runs on edge environment. Due to the fact that it relies on a heavy backbone(FPN), it is really troublesome if we want to deploy this architecture in realtime.
In order to remedy this, another group of researchers proposes some techniques to accelerate the inference speed:
-
Use TensorRT as deployment environment. TensorRT from Nvidia is quite famous for its ability to accelerate model inference on their devices. An important point shown by them is that we should use Mixed Precision Strategy. It means that we could encode different subnets at different floating-point format in order to achieve better trade-off between speed and accuracy.
-
Exploiting Temporal Redundancy in Video
As can be deduced easily, we don’t have to estimate segmentation mask at every frame when dealing with video since it tends not to differ much between consecutive frames. So the questions are:
- How to choose frames to fully execute the whole network?
- For the rest, what will we do?
For the first one, it seems that we could only choose arbitrarily as there is no specific rule for this. In the paper, they choose 1 frame in every 5 frames as key-frame.
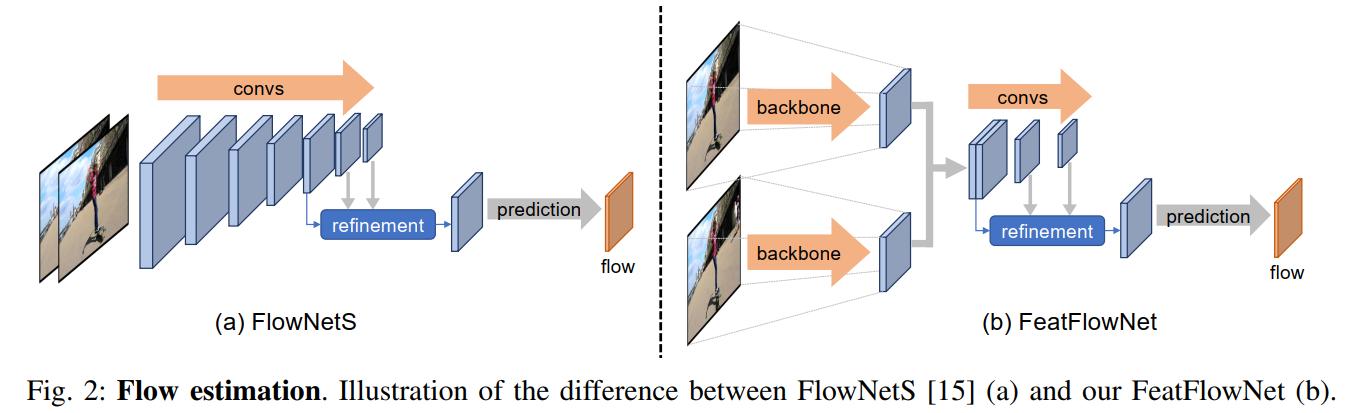
For the second one, this paper proposes a strategy called Partial Feature Transform. This strategy skips computation in certain high level, which is intuitive in my opinion. More abstract feature tends not to change enormously between consecutive frames. If you want to know exactly which layers to skip in Yolact Edge, feel free to read the paper. Now, if we skip the computation in non-keyframe, which happens instead? In this case, the authors choose to estimate the output of these layers by transforming the corresponding output in the nearest keyframe by using a pretrained network called FeatFlowNet. Please note that this network is non-learnable during training process.
Personal thought
I have to say that I don’t really like this architecture for two reasons:
-
It depends heavily on detection branch for association, therefore it produces unnecessary overhead like the bounding boxes, etc.
-
I feel like it is just a patch to equip object detection model with another ability instead of a standalone segmentation architecture.
Thus, in my next post, I would love to introduce another architecture, which I prefer to YOLACT line