Another post insprired by an interview failure. During a chat about a position in speech processing area, interviewer asked me about the differences between attention and self attention. I, at that time, who only have a vague understanding about these two, started to invent something about these two to make up for the lack of knowledge. That’s the reason why we have this blog. Eventhough the names are quite alike, they are not really much in common, except for the fact that they are used intensively in NLP and speech processing. Without further ado, let’s jump right to it. Please notice that this blog is only to indicate the difference in high level. I won’t dive too deep into them.
Attention
Attention mechanism comes hands in hands with encoder-decoder architecture, which is widely used in several seq2seq applications like machine translation, text summarization, etc. Basically, this architecture tries to recap the information from input and then produce output. How to do that? Encoder will process each token from input and distill the knowledge it learns into a context vector. This context vector will be the main source of information for the decoder to assemble the output recursively.
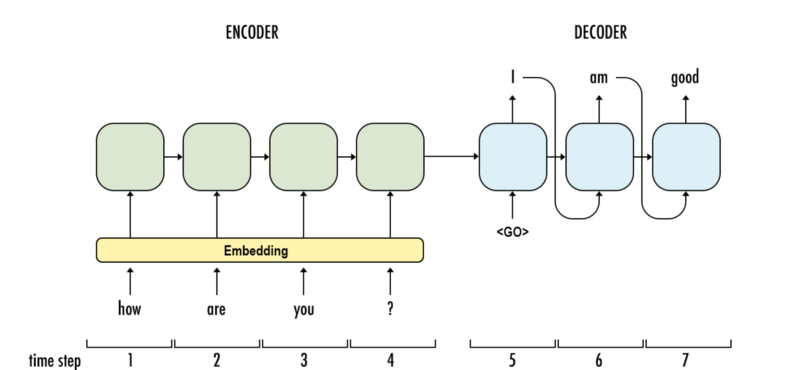
As can be seen, the context vector becomes the bottleneck, especially when the input length get longer and longer. In this case, a vector with predefined length cannot capture effectively the information encoded from the input. It does sound like the concept of long term dependencies in RNN, right? But don’t get confused between them eventhough they are quite similar.
How to resolve this issue? An obvious solution is that instead of using the last hidden state from encoder as context vector, we employ hidden states from intermediate stages too. Furthermore, we also have a mechanism to choose the ones which is more relevant to the current output. And it is the core of Attention mechanism.
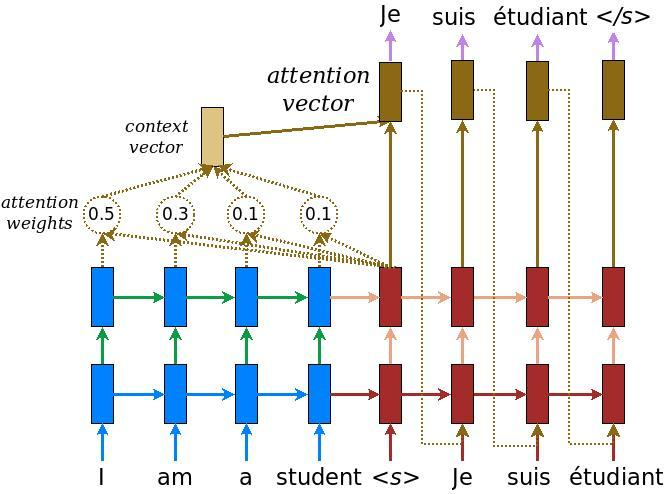
You may wonder how to produce the weight for each encoder hidden state? Well, in conventional encoder-decoder, in order to fabricate a token, we need hidden state from the previous step as well as the context vector. With attention mechanism, we will have a small FC layer which takes this previous hidden step and every encoder state, compute the similarity score between them and use this as relevance weight. That’s it.
Self Attention
What about self attention? Self attention is the core of transformer, which fuels the advancement in NLP for the last 5 years? Let’s take a look at that.
Obviously, when we talk about sequence processing, RNNs will be mentioned. Its recursive design is optimized for this type of input. However, it is suffered substantially by long term dependencies. Its variants like GRU and LSTM can only tackle with this issue to some extent. And transformer with its self attention arrives to handle this problem once and for all. Notice that self-attention has nothing to do with encoder/decoder architecture, this self-attention module is used to replace the traditional RNN and its variant. It receives a sequence of n tokens and outputs another sequence of n tokens too, just like RNN.
The key idea here is: Instead of processing sequentially, token by token like RNNs, we can process the whole sequence at the same time. Given that we have an input of n tokens, we allow these tokens interact with each other to see which we should pay more attention to when producing output token. Furthermore, we also employ positional encoding in order to insert sequence order information to this module.
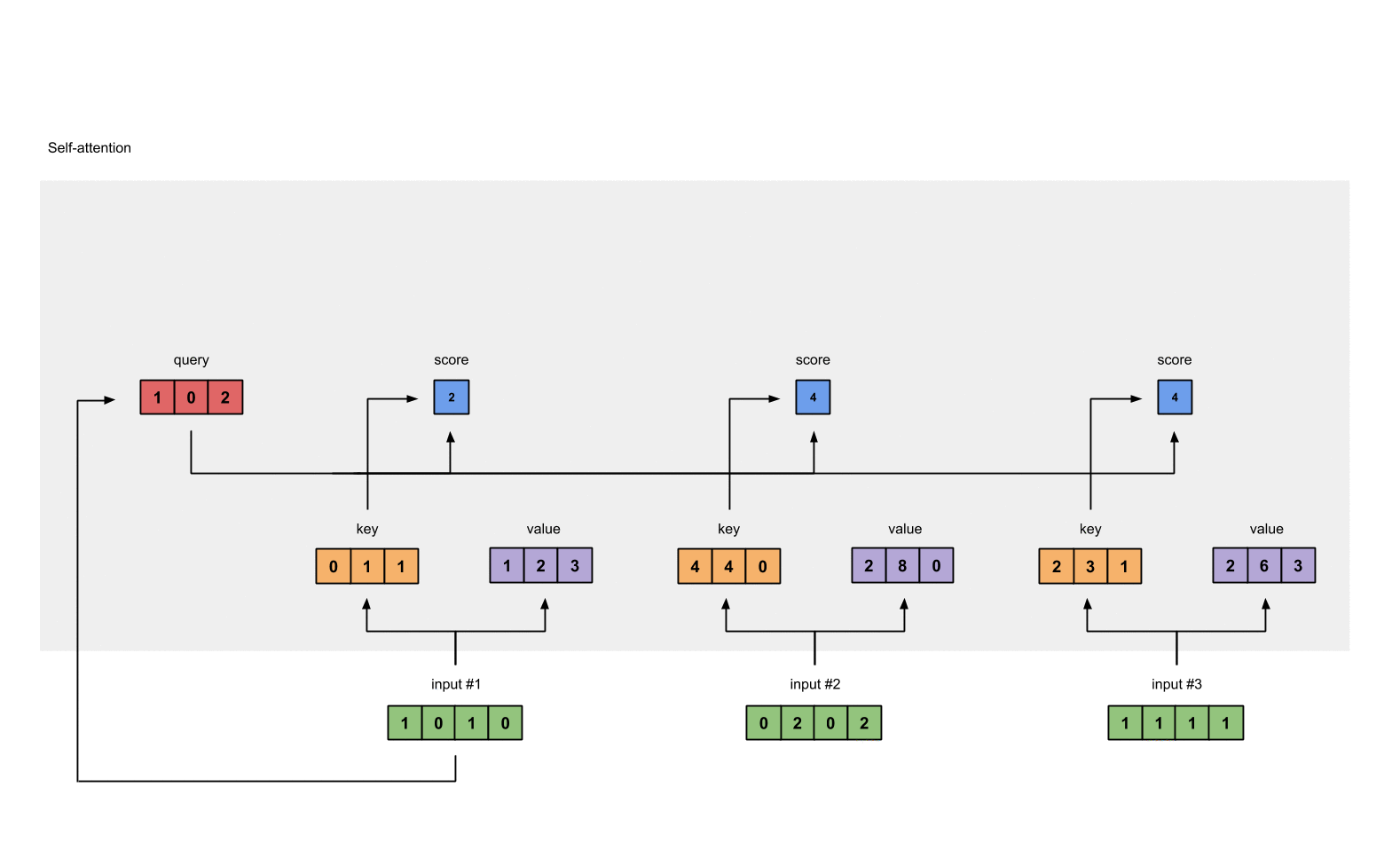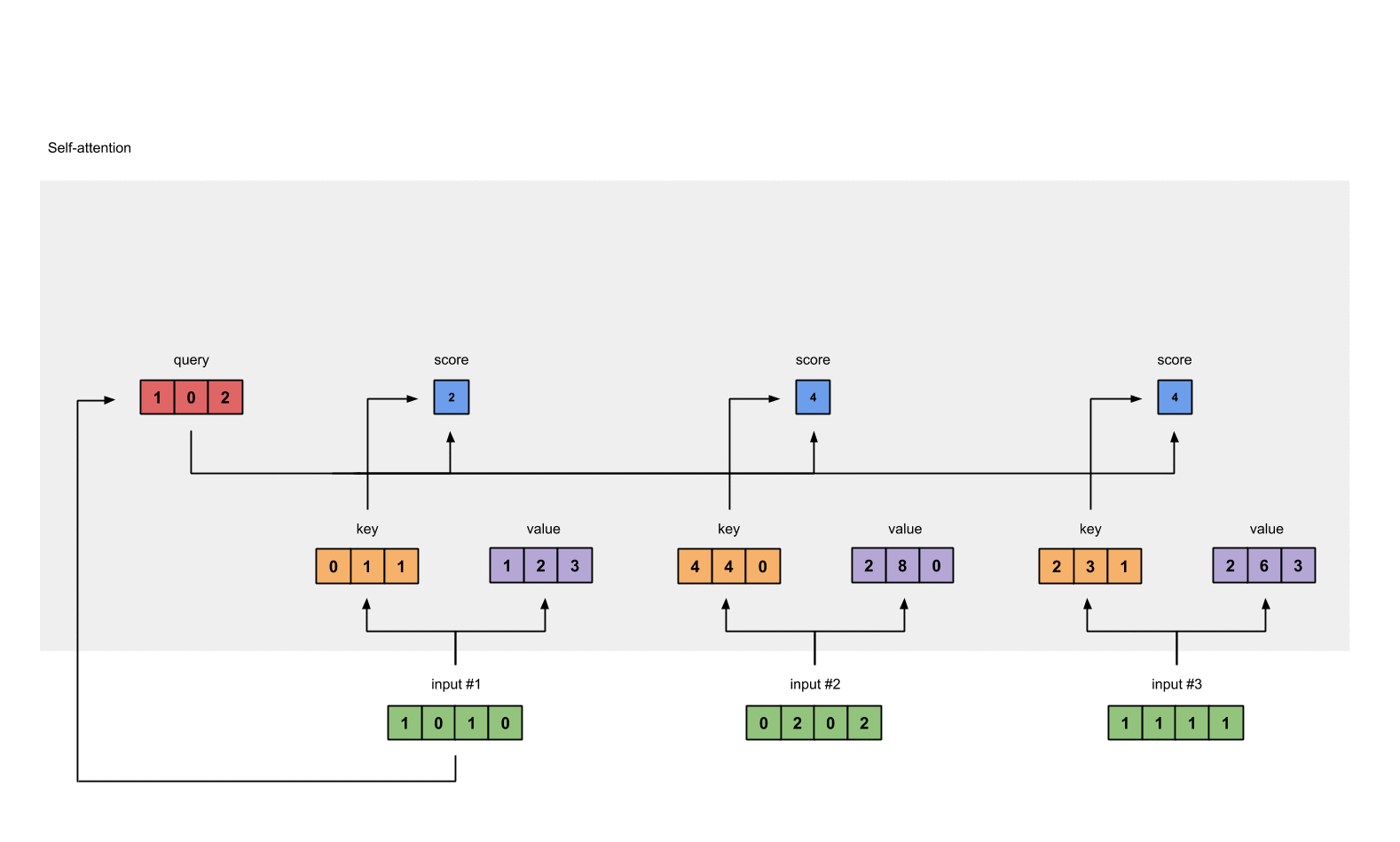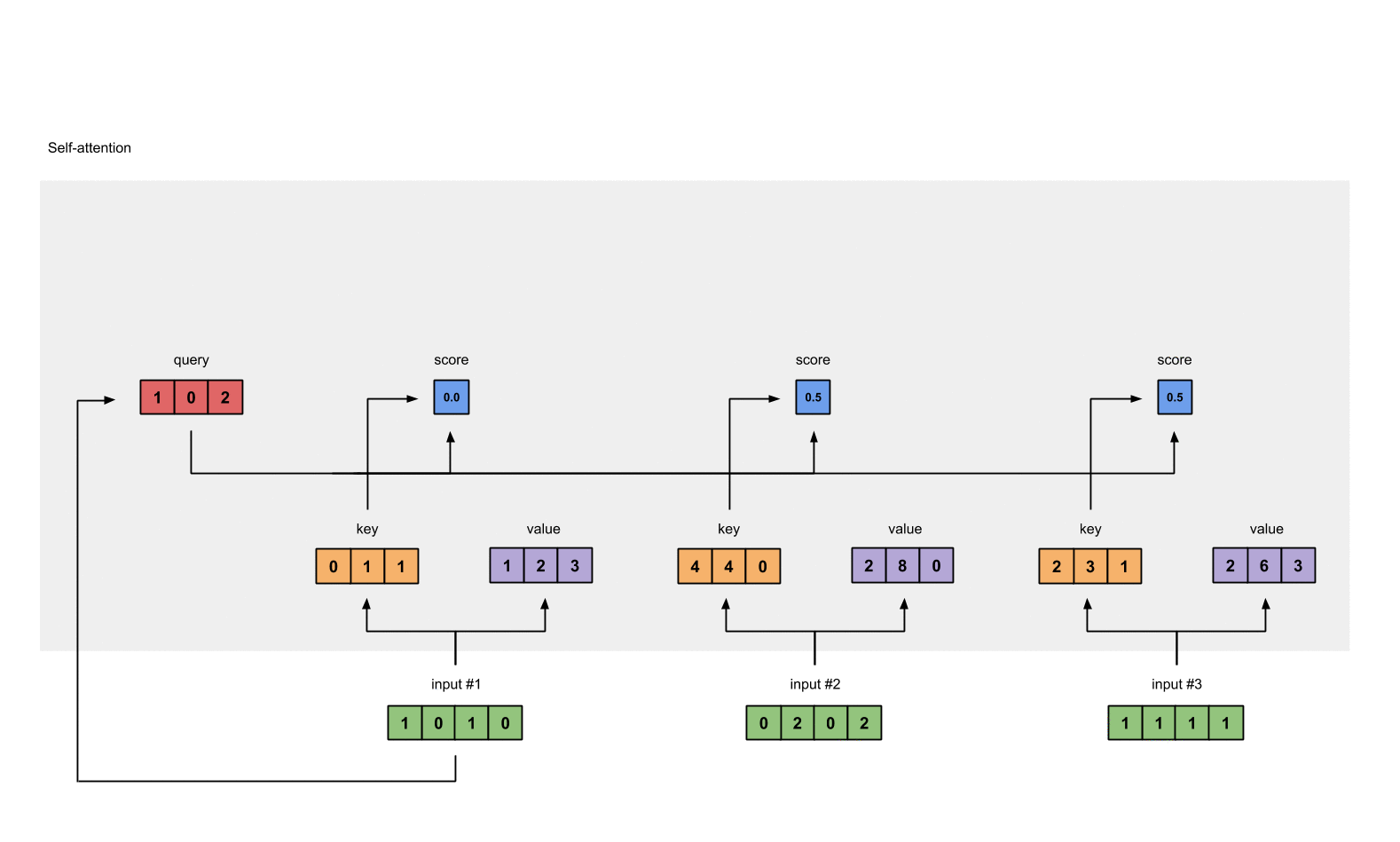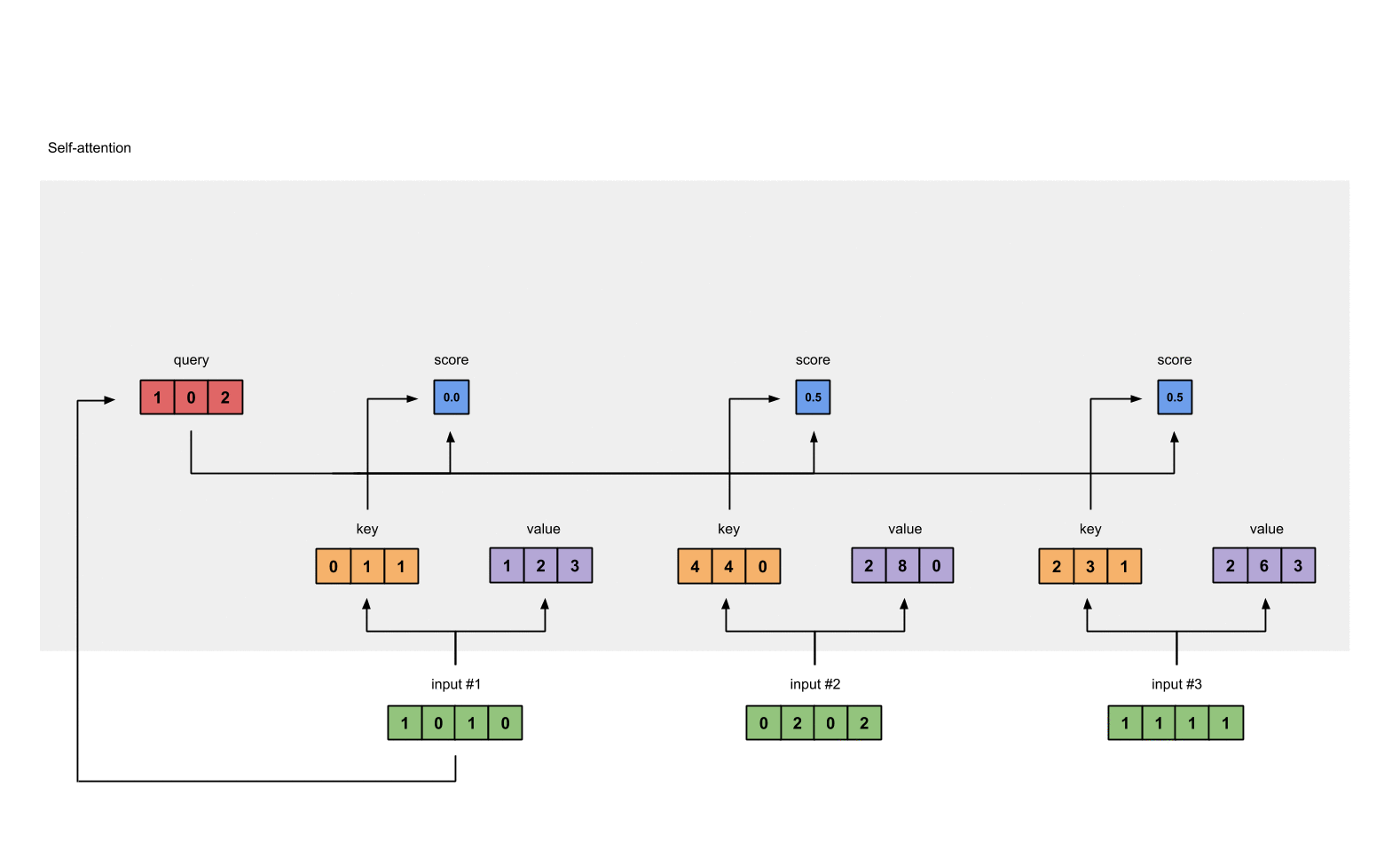
How self-attention does that? I believe tt borrows the idea and also the terminology from database system. Each token will produce a set of 3 vectors: key, value and query. They are created by matrix multiplication and the weights will be learned with optimization algorithms. key and query will represent its corresponding token. For example, when we want to evaluate the influence of every token in the sentence to token a, we use \(q_a\) to multiply with every \(k_i\) in the sentence, including itself. With this weight vector at hand, we use it to multiply with value matrix to have the final output for this input token.
That’s the high level. Now I will go through every step with the help of some images.
-
Firstly, each embedding vector is multiplied with three sets of weight in order to create its
query,value,key.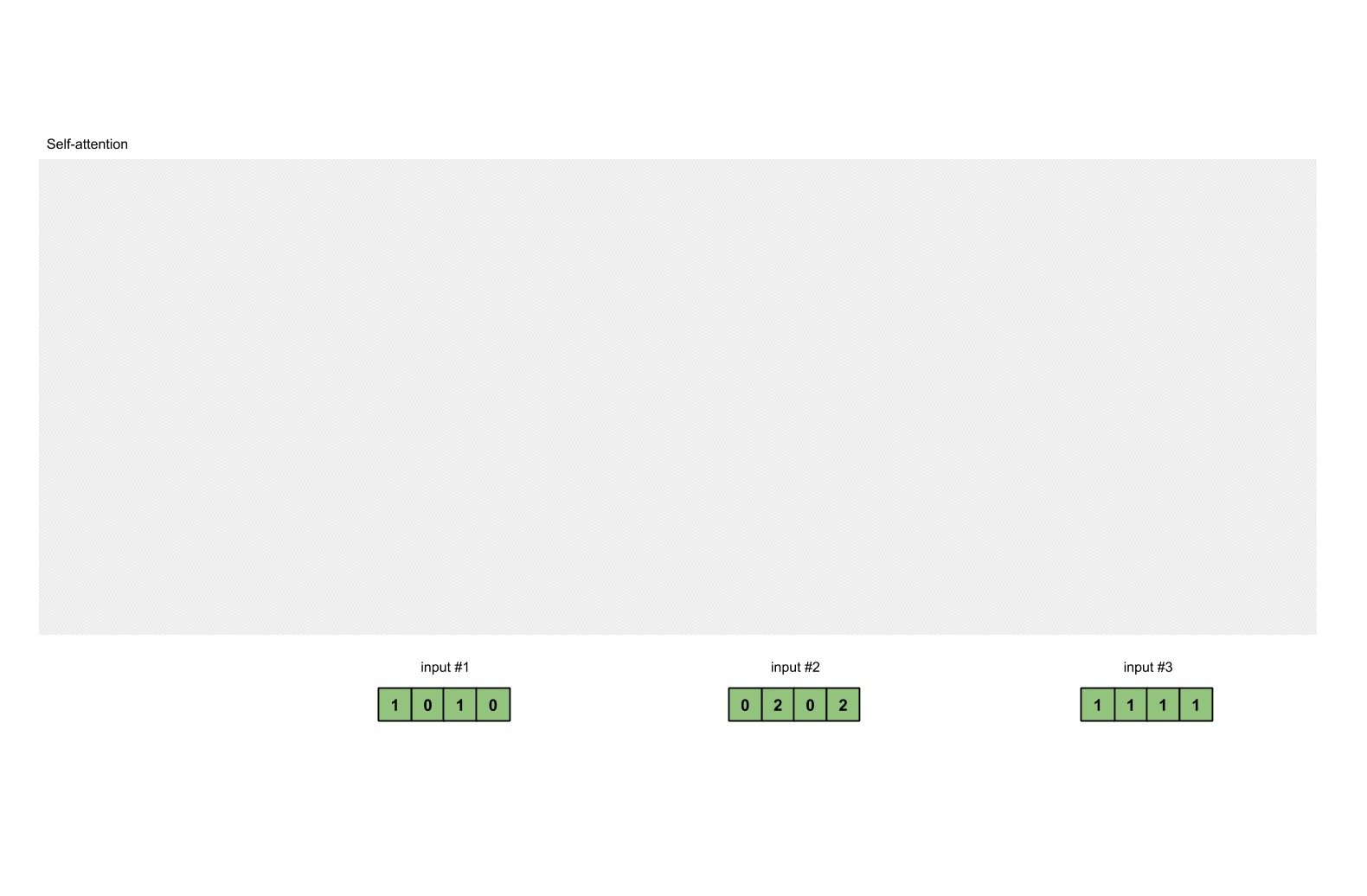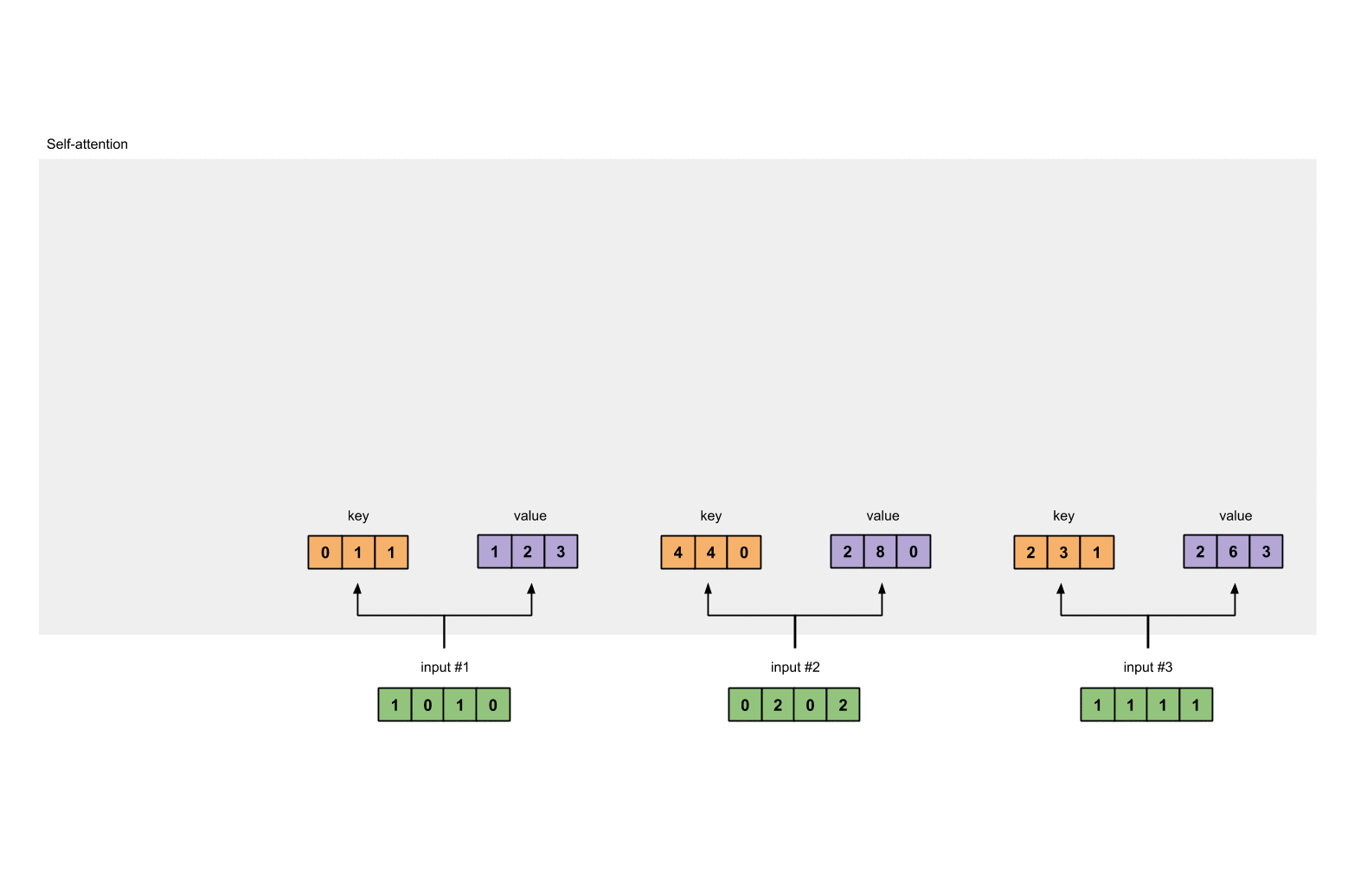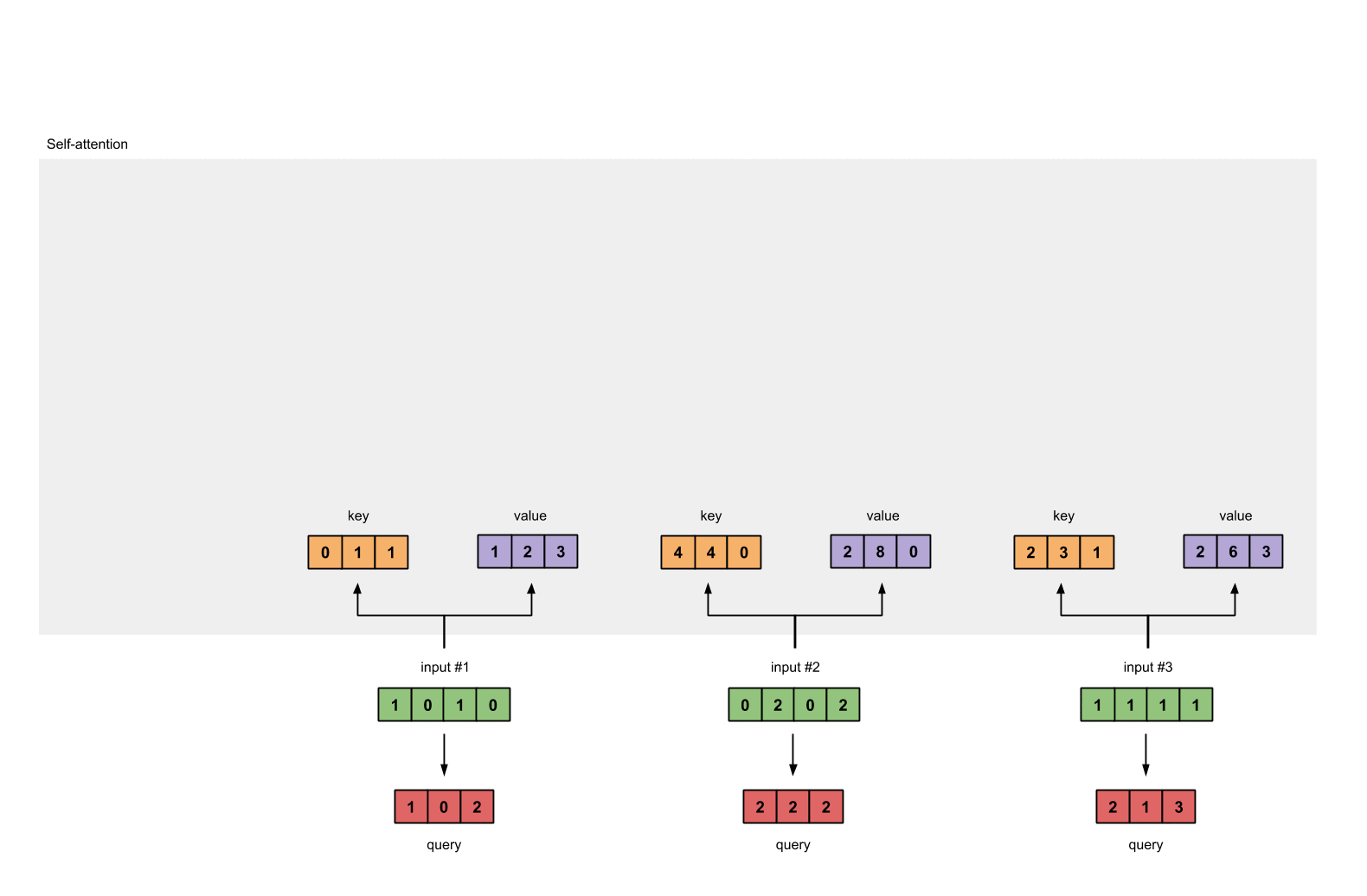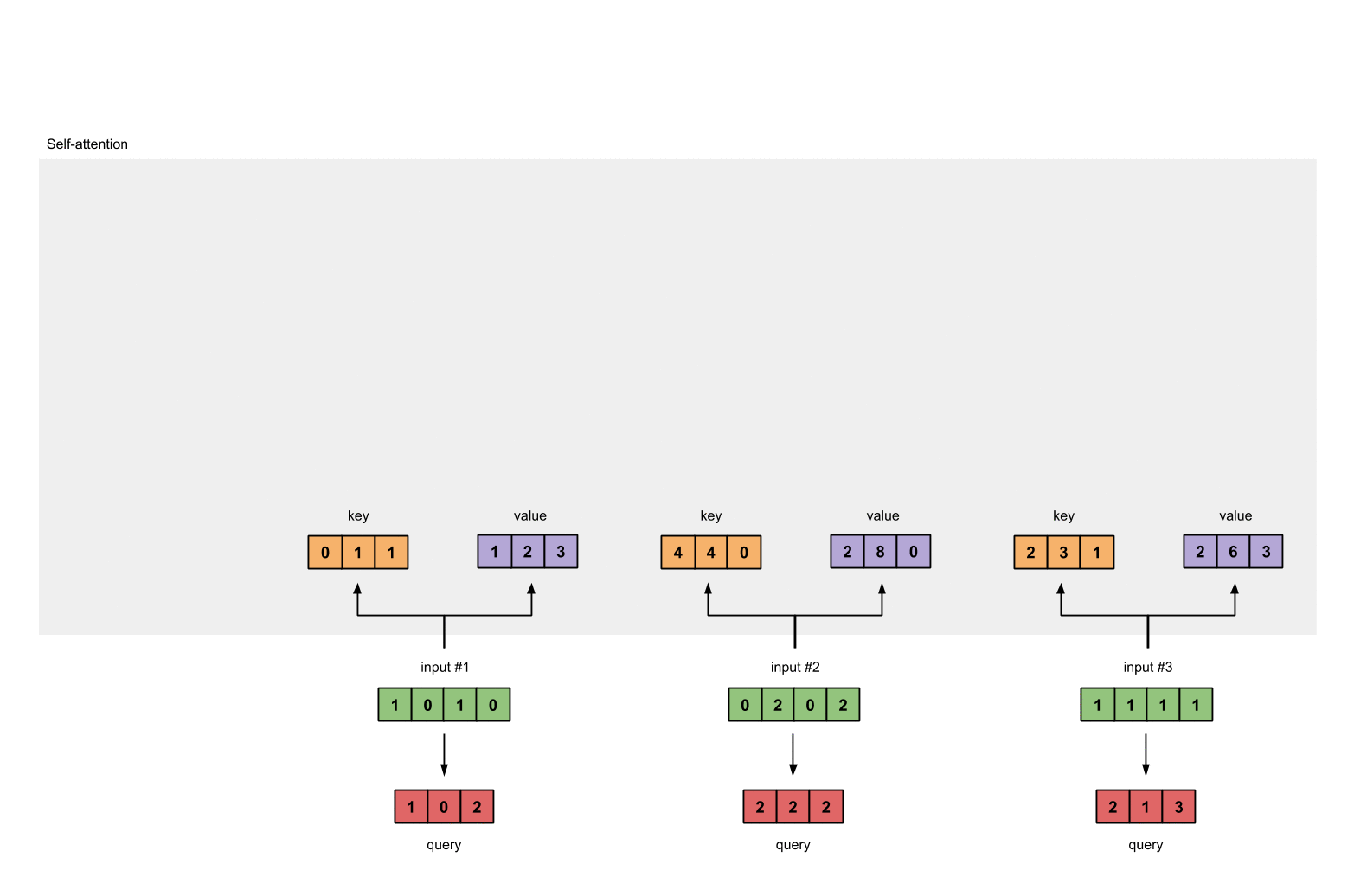
-
Attention score for each position is computed by multiplying the current query with all the
keyin the sequence.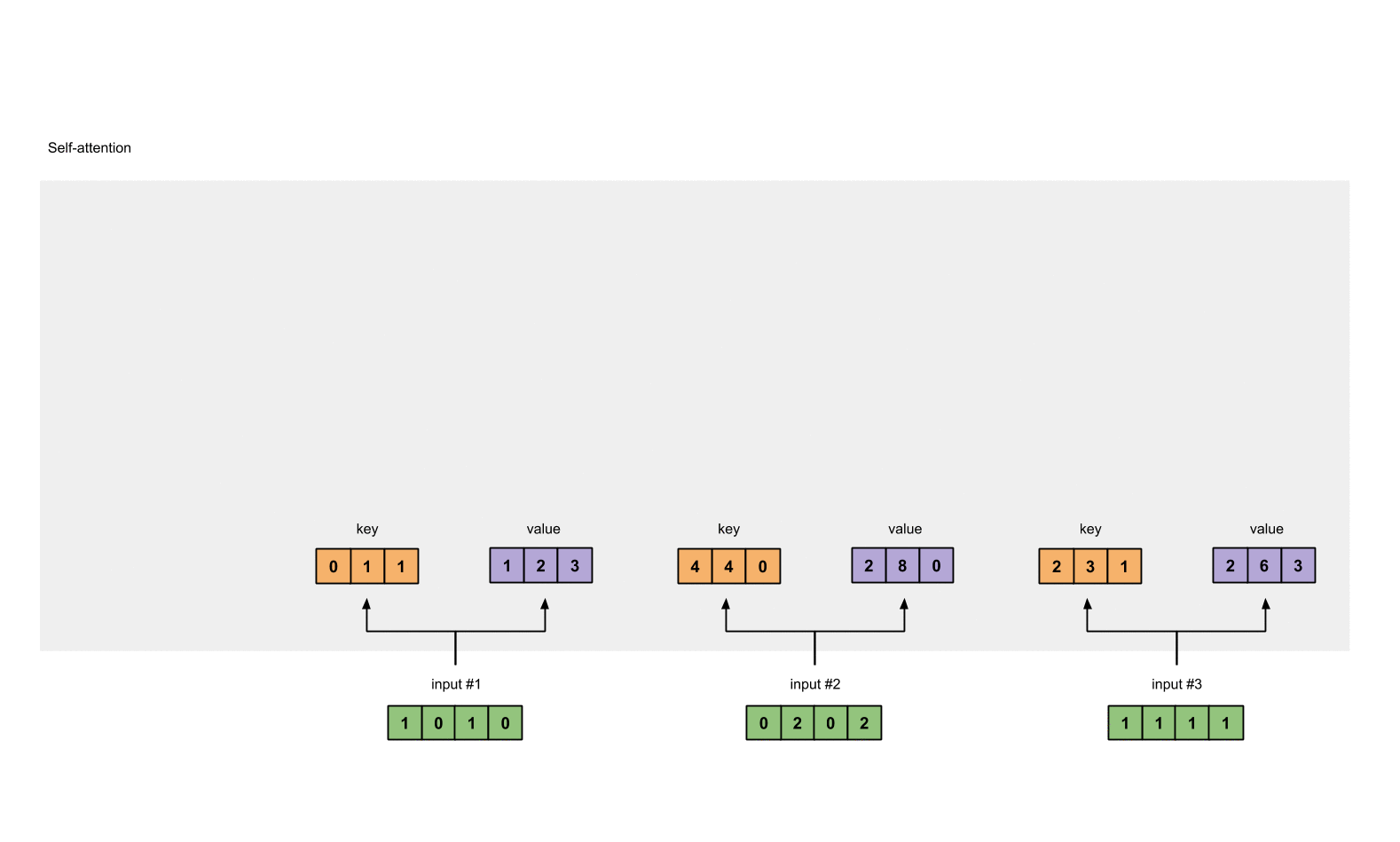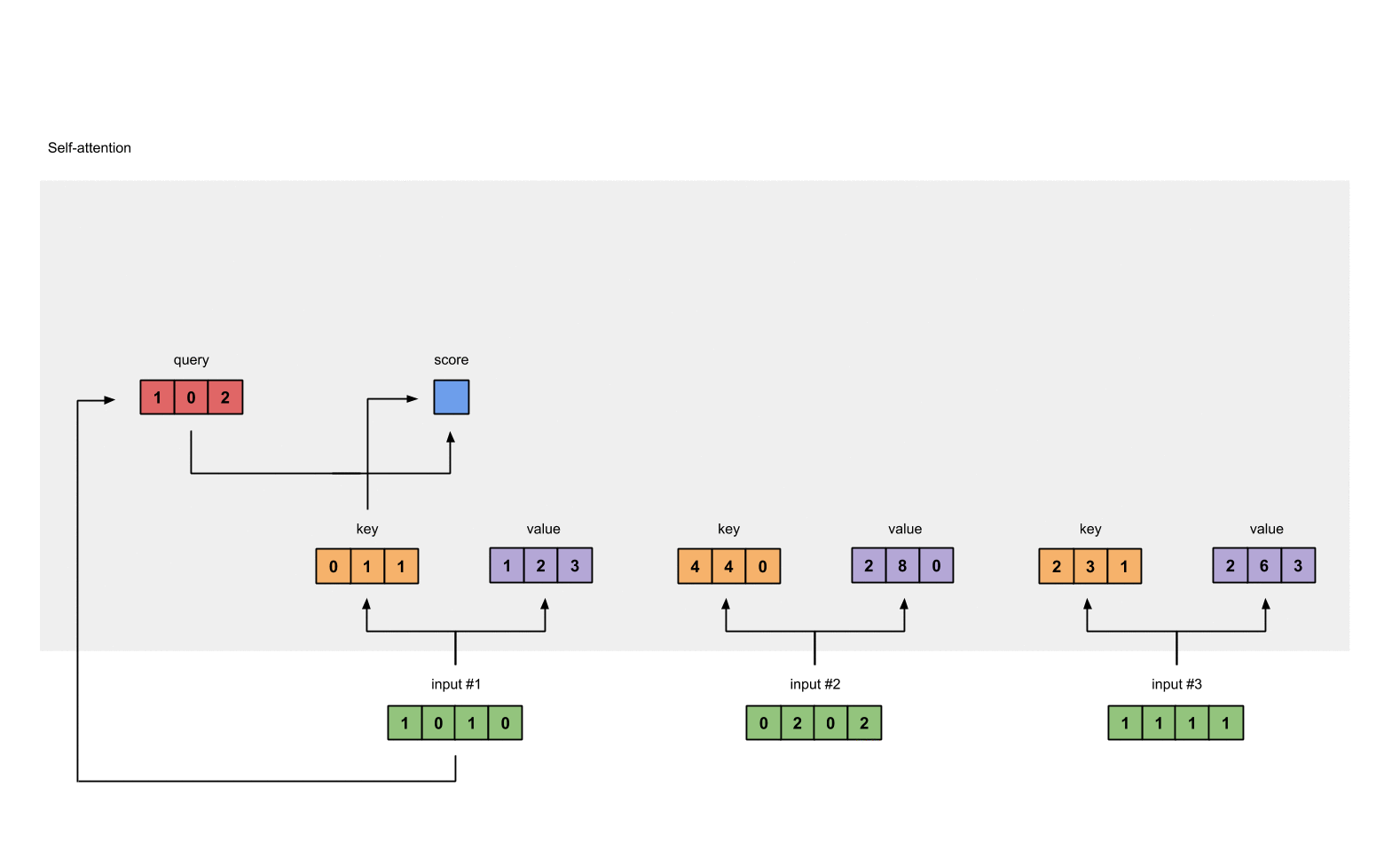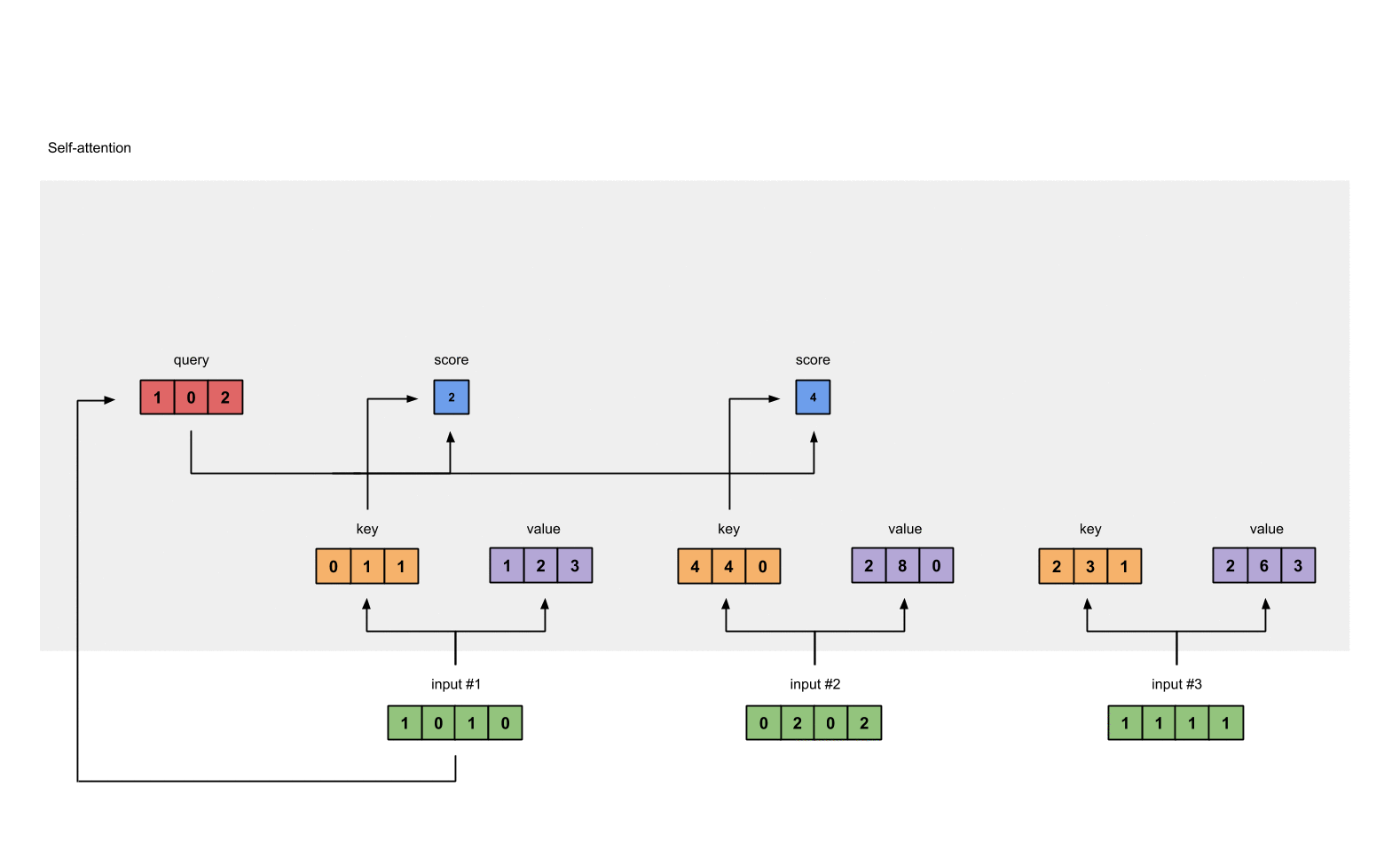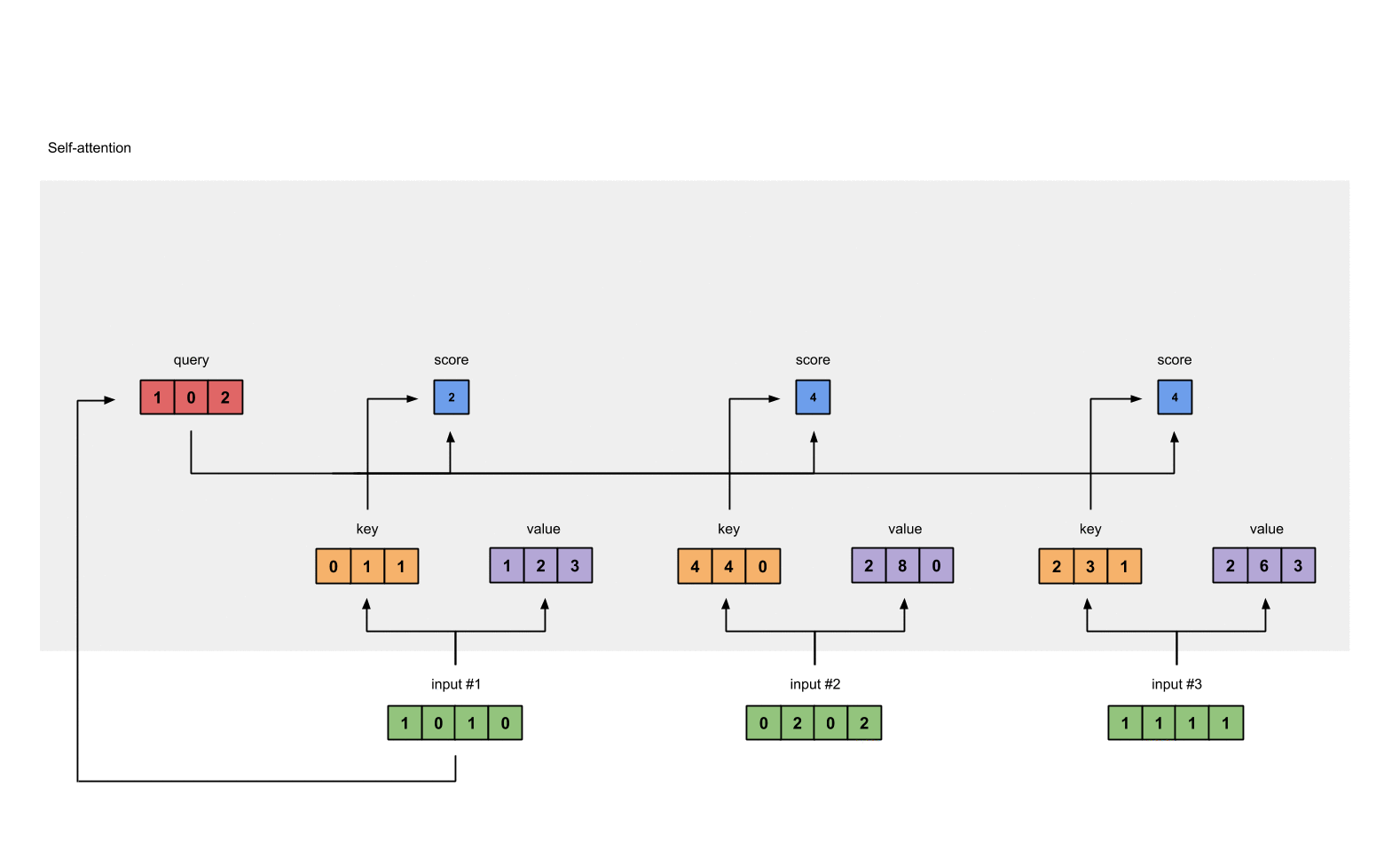
- These scores will be processed by softmax in order to have the sum of 1.0
-
We multiply each softmax score with the
valuevector in order to obtain the influence of each input to the current output.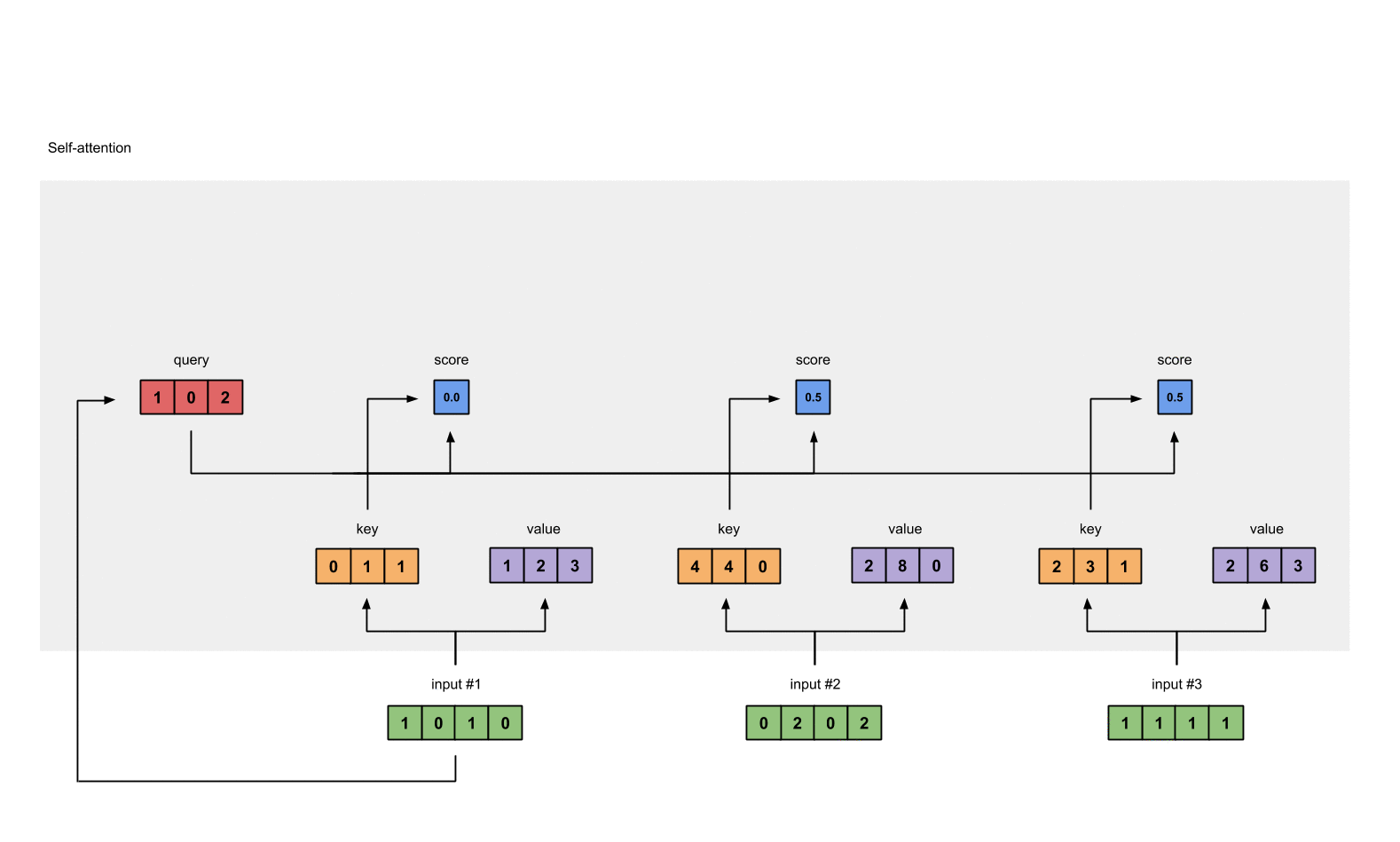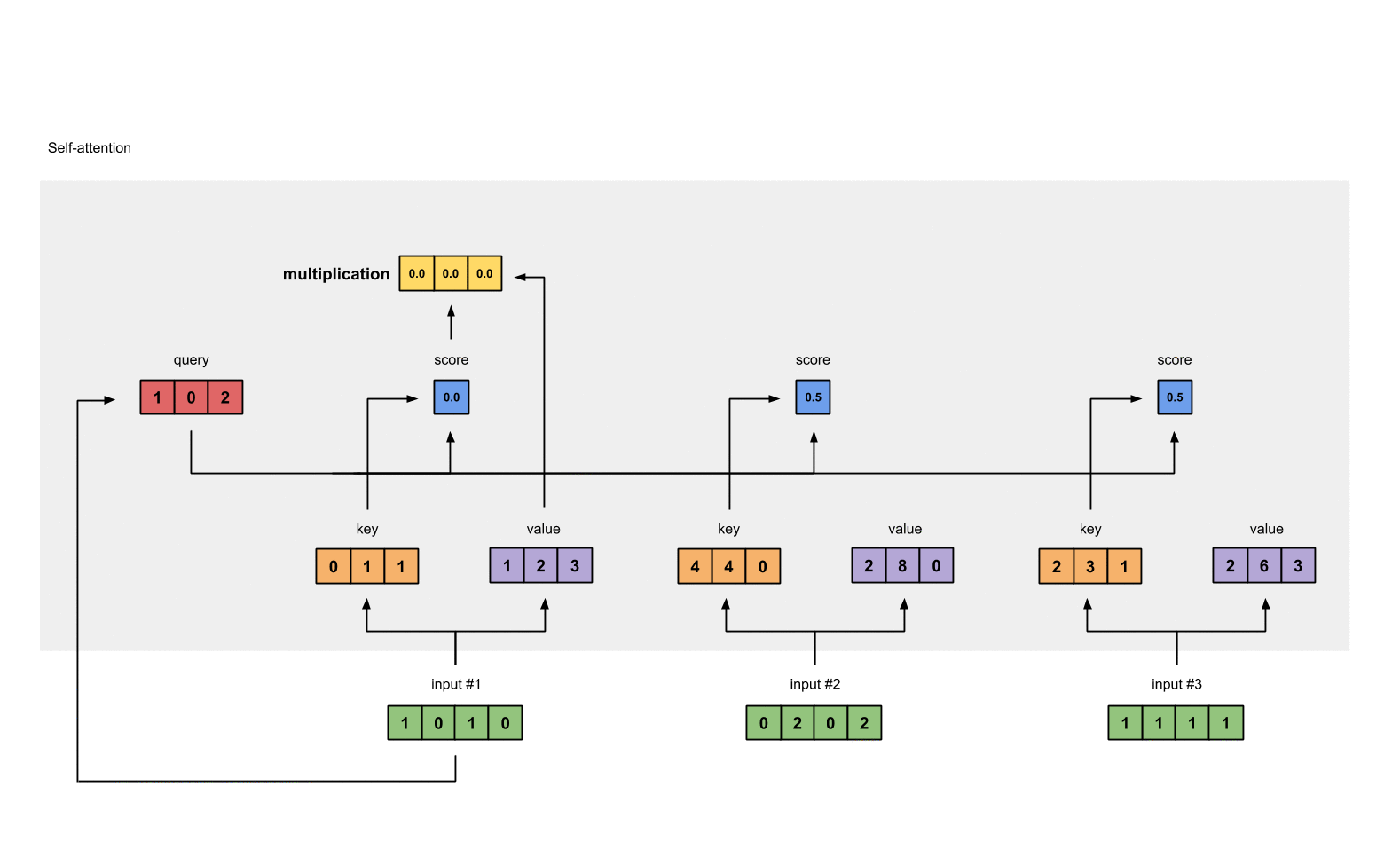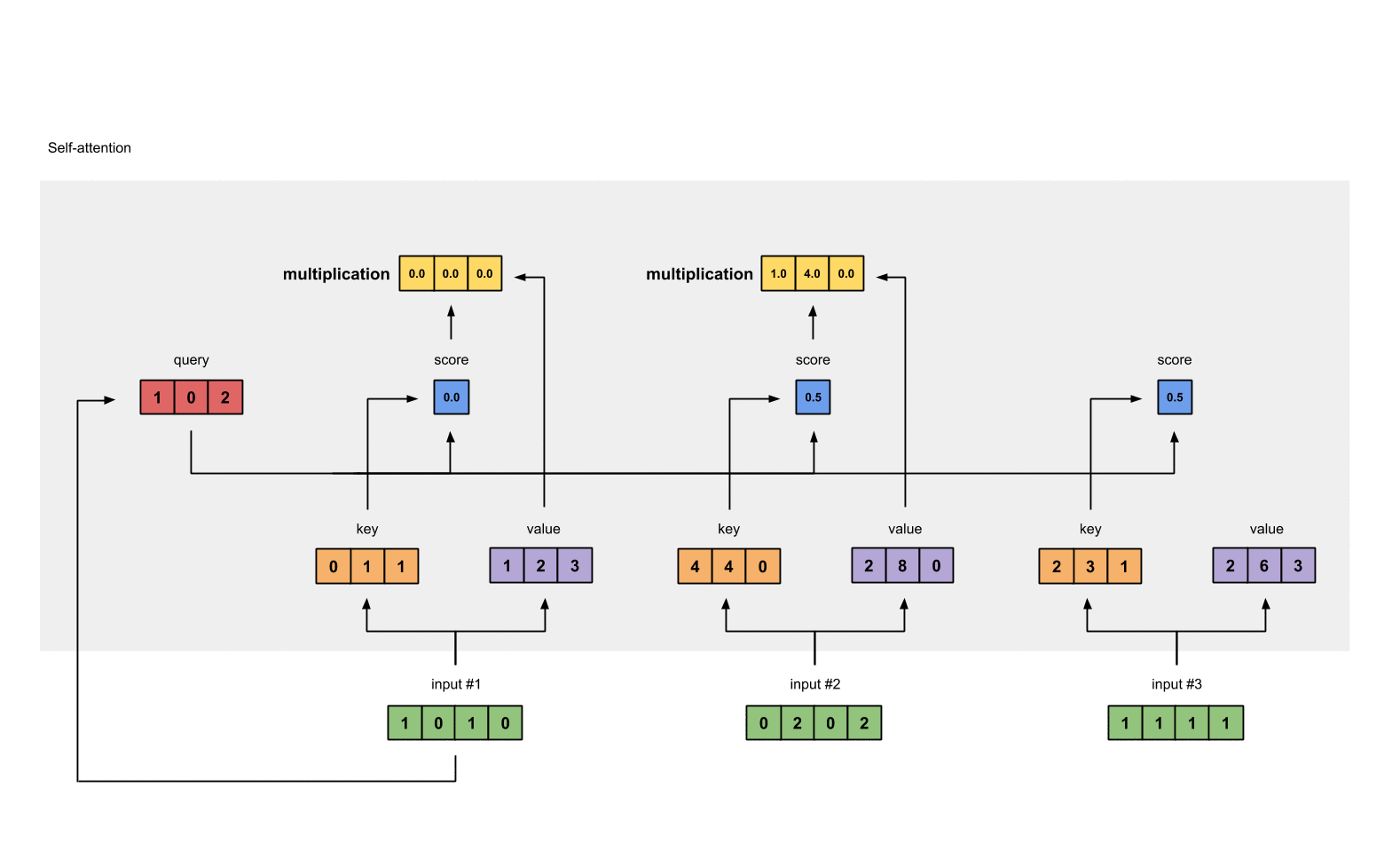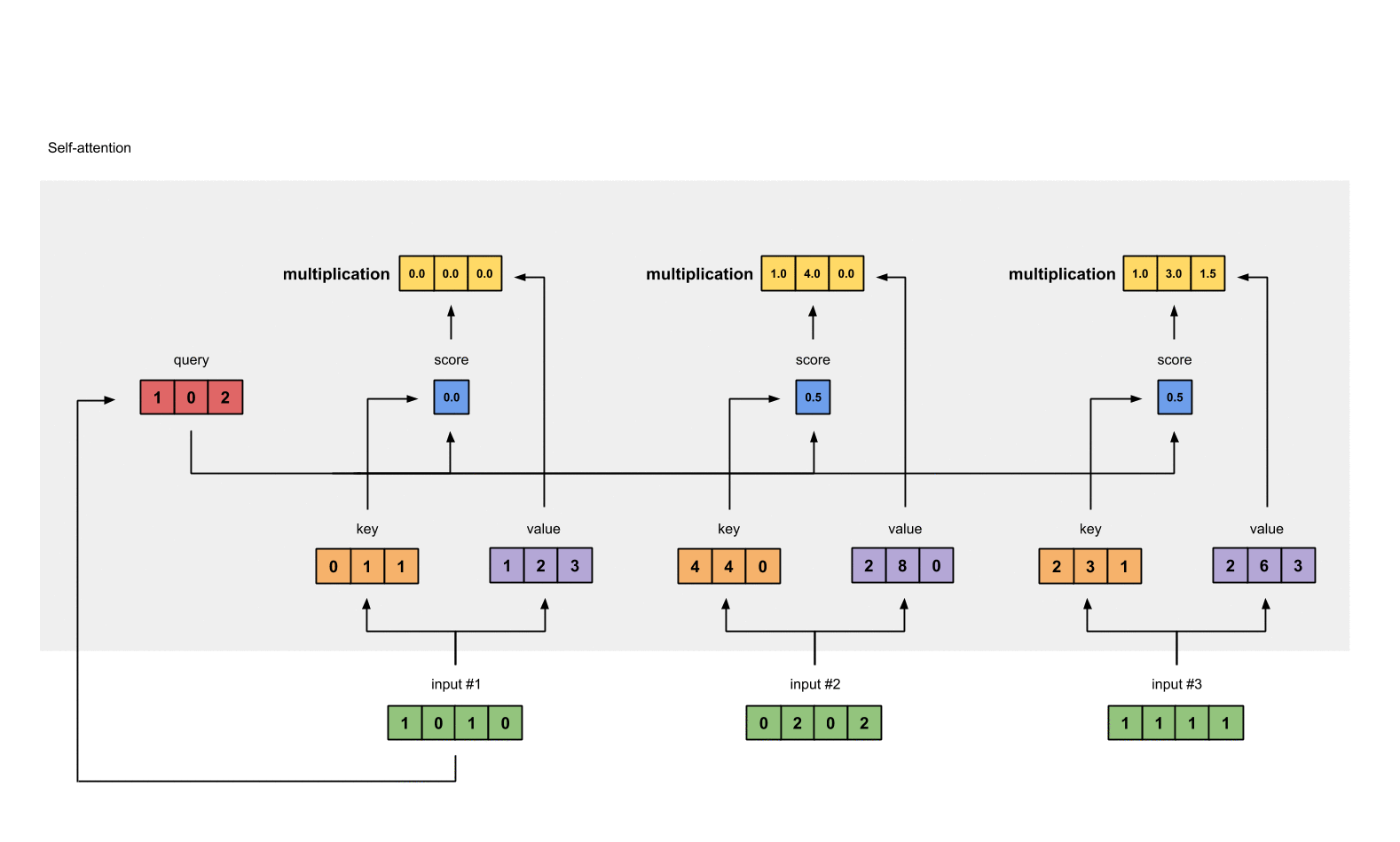
- Every above component will be summed in order to get the actual output for the current position.
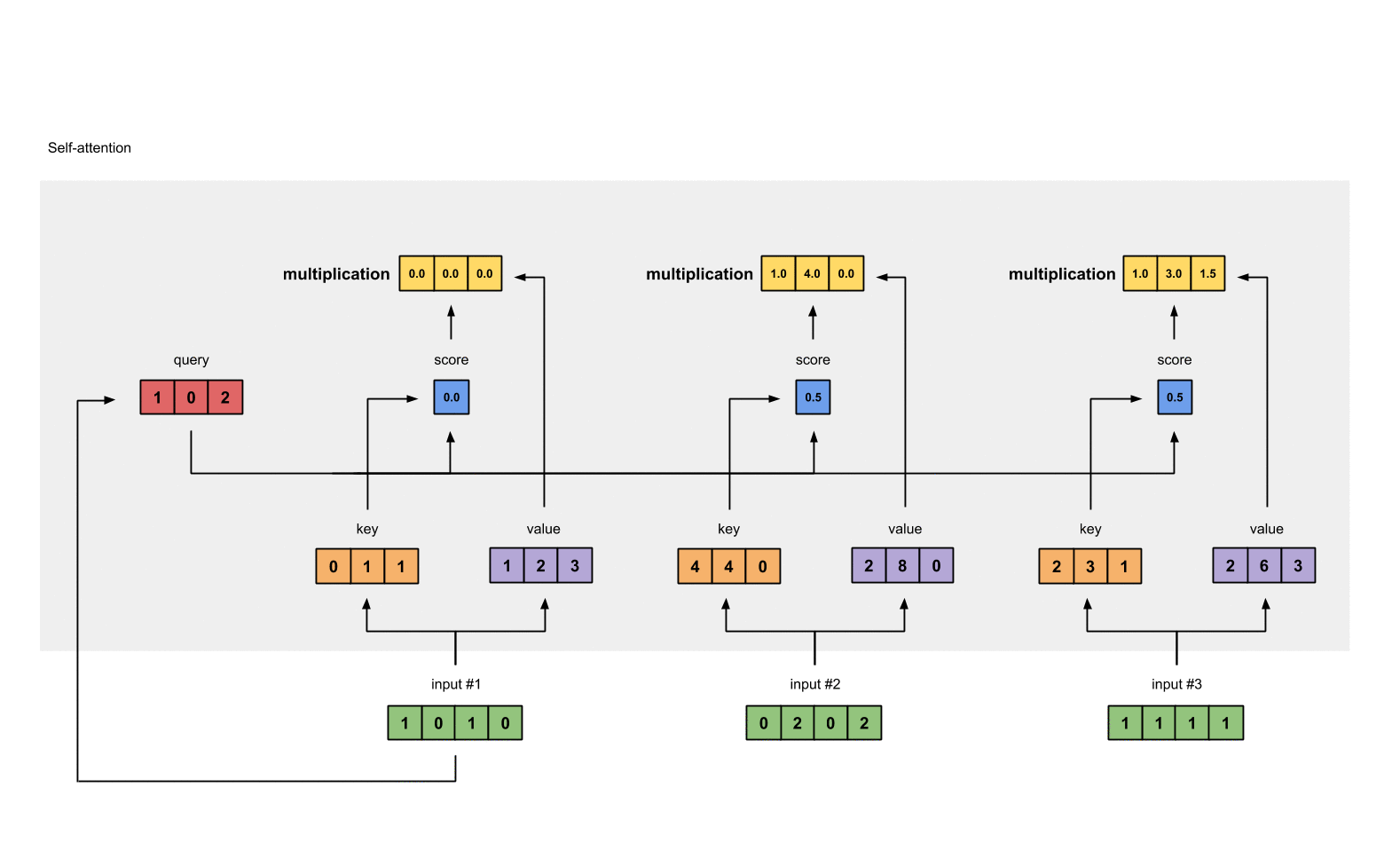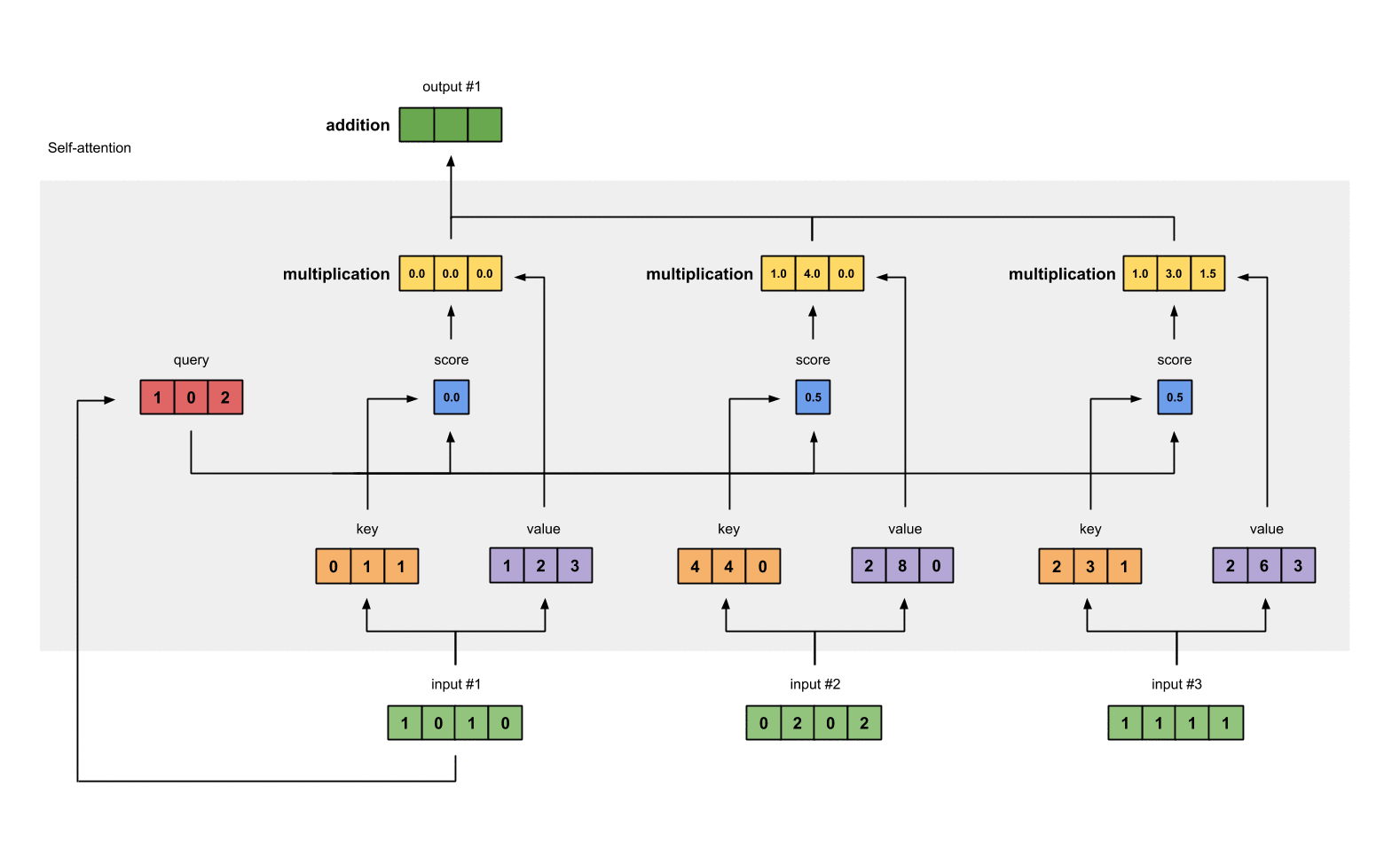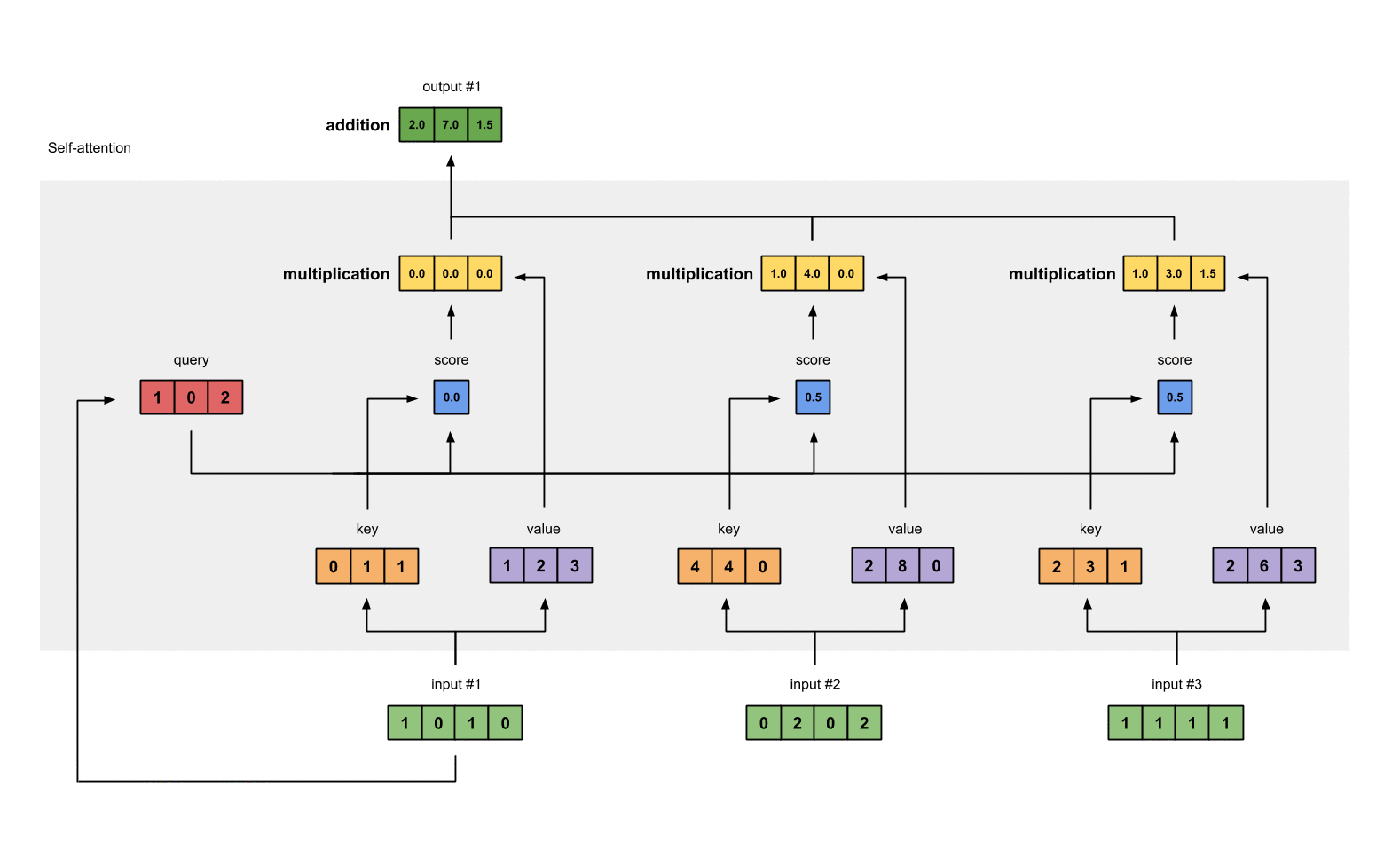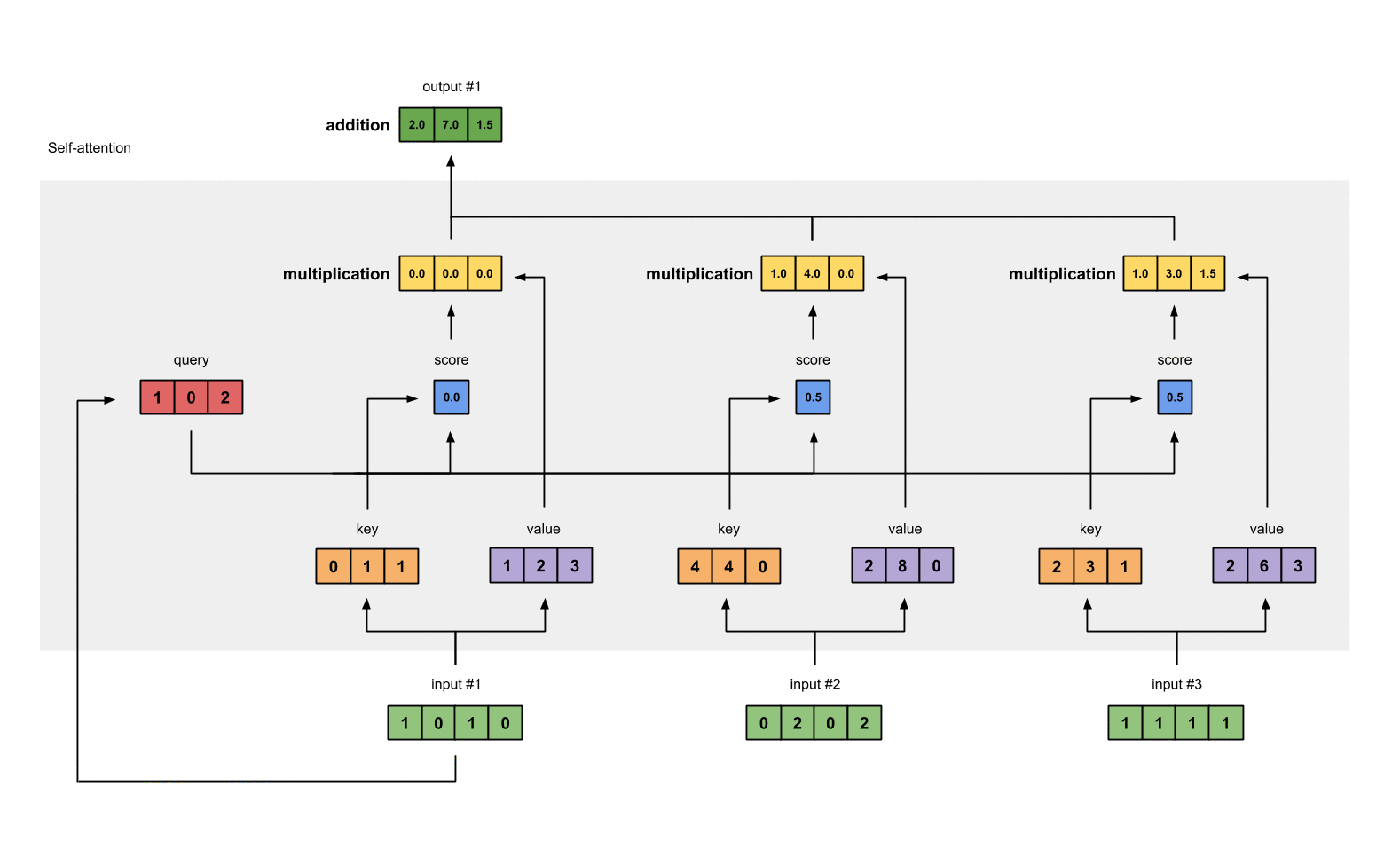
It seems a lot of computations have to me made in order to make it happen, however, it is truly computationally efficient with the help of vectorization.
Conclusion
As you can see, attention and self-attention have little to do with each other. While the former tackles with the bottleneck of information between encoder and decoder in seq2seq architecture, the latter provides a scalable way to process sequential data parallelly. In the next blog, I would love to talk more about Transformer, which is one of the most phenomenal architectures in the history of Deep Learning.