Modern text-to-speech systems are a two-part pipeline: a model that converts text into an intermediate acoustic representation (a mel spectrogram), and a vocoder that converts that representation into raw audio. This post walks through how each part works and where the interesting engineering happens.
I’ve spent quite a lot of time studying TTS systems, more specifically acoustic models. To be fair, this module is the most actively researched in the whole pipeline. In the beginning I wasn’t a big fan of speech processing because of the vagueness of some terms like prosody and timbre — but I like it more now. Below are notes from that process.
Key components of TTS system
In modern TTS system, there are arguably 3 main modules which help to transform text to sound waveform that we can hear and understand:
-
Text analysis. It transforms text to linguistic features. Nowsaday, it is mostly comprised of text normalization and graphene-to-phoneme conversion. Text normalization is to clean the input text and replace number/abbreviation with their standard word format. Then, graphene-to-phoneme is to get the phoneme representation from the word format. This step is optional since the subsequent model can work with characters also if we have enough data.
-
Acoustic model converts text features to acoustic features, which is melspectrogram most of the time. Melspectrogram is chosen since it emphasizes details in lower frequencies, which are critical to speech intelligibility, while de-emphasizing higher frequencies, which are dominated by noise burst. This is supposedly the most important module in TTS system due to the task complexity and data shortage.
-
Vocoder model transforms linguistic features a.k.a melspectrogram into speech waveform. This module seems easier to build than acoustic model because of the data nature.
People are working on end-to-end systems which can produce waveform directly from linguistic features. This approach has many upsides: it requires less data preparation, avoids error propagation in cascaded models, and should reduce the cost of development and deployment.
However, it still has a long journey ahead. The task is complicated mainly due to the different modalities between text and speech waveform — in particular, the large difference in sequence length between the two. That’s why the community tends toward a progressive approach, breaking the task into sub-tasks for better control.
Acoustic Model
As mentioned earlier, acoustic model transforms linguistic features (batch, seq_len) to melspectrogram (batch, num_feats, feat_embedding). Here I focus on neural-based network only. There are several ways for us to approach this module:
-
Architecture: RNN-based (Tacotron family), CNN-based and Transformer-based (Fastspeech family). The first and the last are more prominent, which is sensible since TTS is a problem of sequence generation.
-
Model Framework:
It can be either encoder-attention-decoder (auto-regressive), where encoder encodes the meaning of the whole text into a vector and decoder uses this information and the current melspectrogram frame to predict the next sequentially.
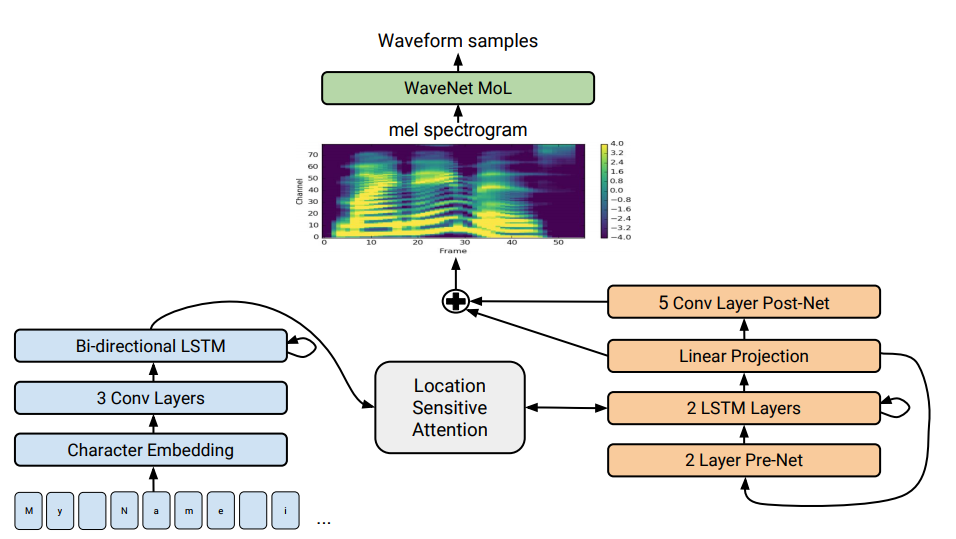
Or Feed-forward network (non-autoregressive) where the computation of the whole melspectrogram is in parallel.
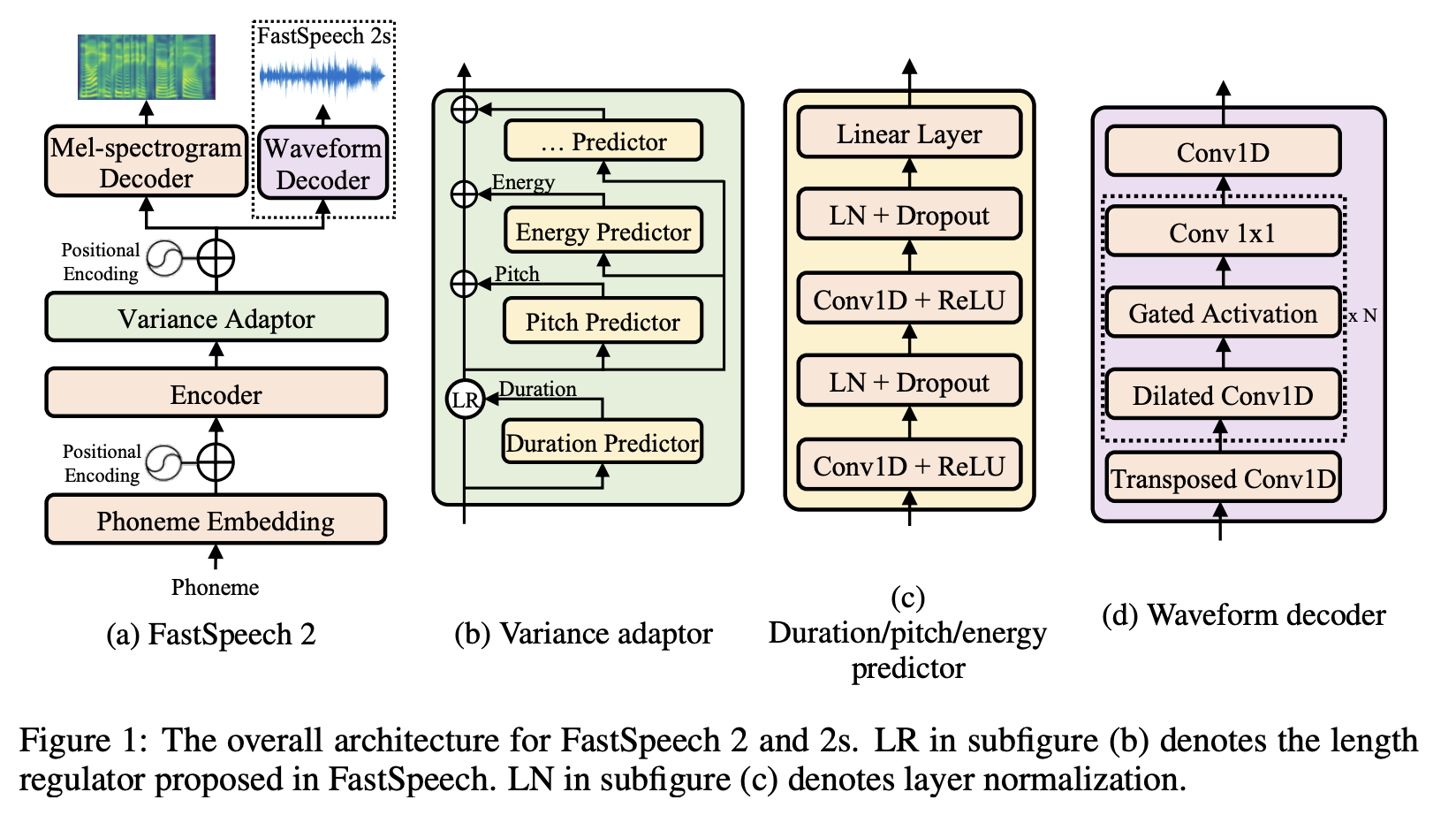
- Data input: it can be either character-based or phoneme-based. This taxonomy is less apparent to many people since the way we treat these inputs is the same. However, while phoneme allows fewer number of token to be predicted and hence better performance, graphene-to-phoneme module is not always available for most languages so character-based seems more convenient for us.
It should be mentioned that
Auto-regressive versus non-autoregressive
I’d like to dive deeper into this taxonomy since this is the most notable difference between two styles of building TTS acoustic model. I believe this distinction comes from the way we want to process the alignment between text and melspectrogram. In other words, how to tell which frames are responsible for that character or phoneme?
-
Auto-regressive: it follows the Seq2seq paradigm where the linguistic features are consumed by the encoder to produce a context vector, and then this knowledge is used to help the decoder produce melspectrogram frame by frame. Alignment is therefore learned implicitly using the attention mechanism.
This makes sense since consecutive frames tend to be similar. However, auto-regressive models are prone to issues like word skipping or word repeating. Moreover, in long sentences the context vector becomes the bottleneck. In terms of performance, it’s quite slow since sequence generation is sequential.
-
Non-autoregressive: it addresses these issues by proposing duration predictor module, each token will decide the number of corresponding melspectrogram frames, hence explicit alignment. This has two advantages: we can produce the whole melspectrogram in one round in parallel and achieve the complete alignment between text and melspectrogram. The biggest issue here is how to obtain the duration label for each token? In practice, there are 3 ways to achieve that:
-
Using ASR model to do the forced alignment. You can find the tutorial here. It works fine, I tested it with my FastSpeech2 with character as input. However, the number of token is limited, therefore, you might have to do the preprocessing a bit exhautively, which may damage the model performance since we have to replace a lot of character with blankspace.
-
Using pretrained auto-regressive model like Tacotron to get the duration. This is a bit counter-intuitive since one of the reason we want non-autoregressive model is the deficiency of auto-regressive model. However, with the advent of Transformer, it has improved a lot.
-
Using unsupervised learning method with alignment network and customized CTC loss function to learn the alignment like this. I don’t think that this module can outperform forced alignment. However, it is convenient and can work for different setups.
Vocoder
Vocoder transforms melspectrogram to waveform. Think of the spectrogram as a musical score — it describes what notes to play and when. The vocoder is the instrument that actually produces the sound.
Vocoder is simpler to build than the acoustic model since we don’t have to worry about alignment: the ratio between the length of melspectrogram and waveform is always the same, which is decided by some parameters like hop_length or win_length. Moreover, since we can generate melspectrogram from waveform directly, the dataset for this task is effectively unlimited.
There are several approaches to build a vocoder, either auto-regressive or non-autoregressive. However, as mentioned earlier, since alignment is inherently embedded in the data, auto-regressive models are less attractive. In the family of non-autoregressive models, GAN can be seen as a dominant candidate. It can be tricky to train this architecture for image generation, but waveform is only a 1D vector so the task is less arduous.
There are some specific techniques which can applied for this task, like multi-scale discriminator or multi-band generator. Nevertheless, GAN as vocoder still follows traditional paradigm, just a stack of layers as generator and another stack of layers as discriminator work together to perfect each other.
-
Multi-scale discriminator: We downscale the original original and synthetic waveform several times and use different discriminators for each scale.
-
Multiband generator: Generator produces several subbands instead of full-band using the same model, i.e instead of producing waveform with 1 channel, we generate 4 channels for 4 subbands. We have algorithm to split waveform into different components with separated sub-bands and merge them into fullband waveform. Melgan and multi-band Melgan are only different in generator part, their discriminators are alike.
Topics to be researched
- How to learn alignment in unsupervised manner?
- Prepare data and train a vocoder from scratch? Study different types of loss function for GAN vocoder. For example, multi-band melgan claims STFT loss outperforms feature matching loss but in HifiGan, they still use feature matching loss
- Adaptive TTS, i.e voice cloning
Final thoughts
The gap between the best open-source TTS systems and human speech has closed dramatically in the last few years. What makes modern systems work is not any single breakthrough but the combination: better acoustic models (non-autoregressive, parallel), better vocoders (learned priors, adversarial training), and more data. If you’re building on top of TTS, the practical implication is that pre-trained models like VITS or Bark are now good enough for most use cases — the interesting work is in fine-tuning for specific voices and domains.