If you’re anything like me, you’ve probably spent the last year or so marveling at what Large Language Models (LLMs) can do. From writing code to summarizing massive documents, they feel like magic. But as I started digging into how they actually work, I realized something important: not all LLMs are built the same way.
Almost all modern LLMs are based on the Transformer architecture, but they use different parts of it depending on what they’re trying to achieve. Originally, the Transformer was a two-part system: an Encoder and a Decoder.
Over time, researchers figured out that you could split these components apart to specialize in different tasks. In this post, I want to walk you through my mental model of these architectures—the original Encoder-Decoder, the Encoder-only family (like BERT), the Decoder-only family (like GPT), and finally, how the two-step inference process actually plays out when you’re chatting with an AI.
1. The Original: The Encoder-Decoder Architecture
Let’s rewind to 2017. Google published the landmark paper “Attention Is All You Need”. They were trying to solve machine translation (like translating English to French), and they came up with a two-part system:
- The Encoder: Think of this as the “reader.” It looks at the entire input sequence (the English sentence) all at once and creates a rich, context-aware mathematical representation of it.
- The Decoder: Think of this as the “writer.” It takes that representation and generates the output sequence (the French sentence) one word at a time.
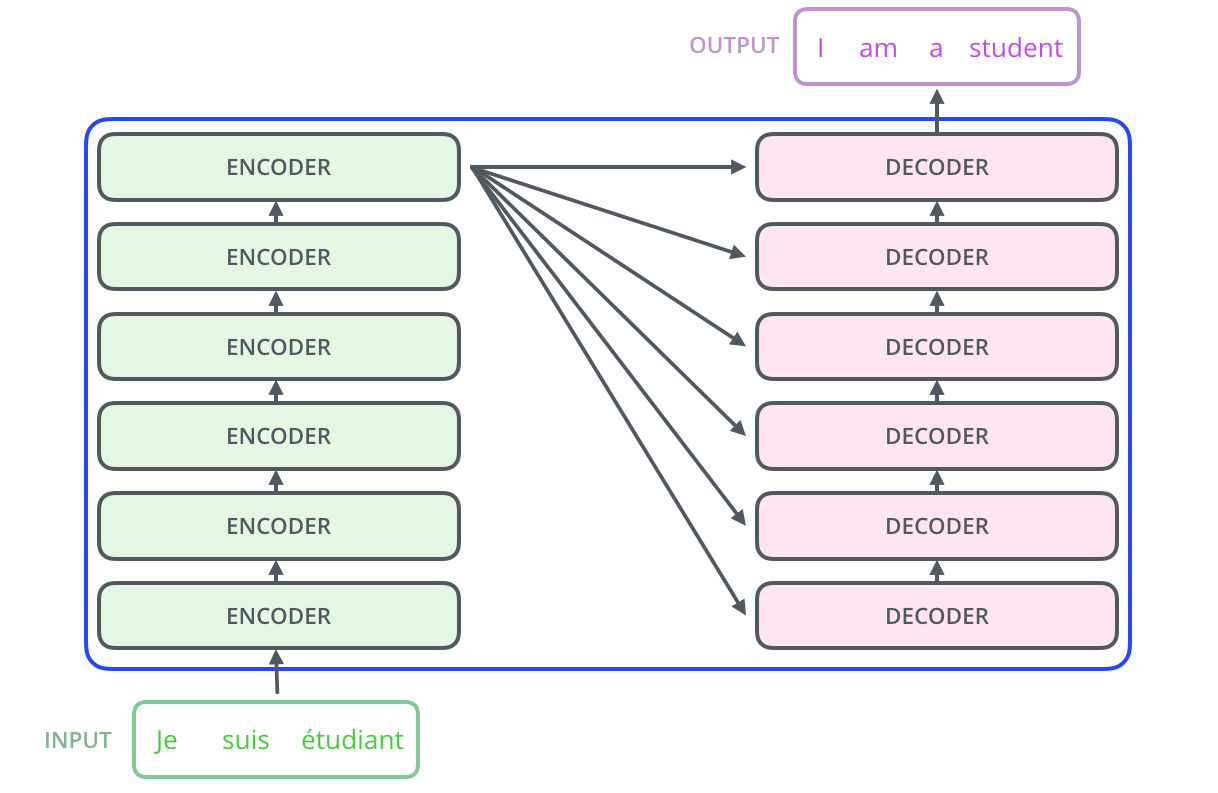
This setup is incredibly powerful for tasks where you have an input sequence and need an output sequence, like translation or summarization (models like T5 or BART use this). But the AI community soon realized that for many tasks, you only need one half of the equation.
2. Encoder-Based Models (e.g., BERT)
If your goal is to understand text rather than generate it, you only need the Encoder.
When I first learned about BERT (Bidirectional Encoder Representations from Transformers), it blew my mind. Because BERT doesn’t need to generate text word-by-word, it can look at the entire sentence at once—both left-to-right and right-to-left. This allows it to deeply understand the context of every single word.
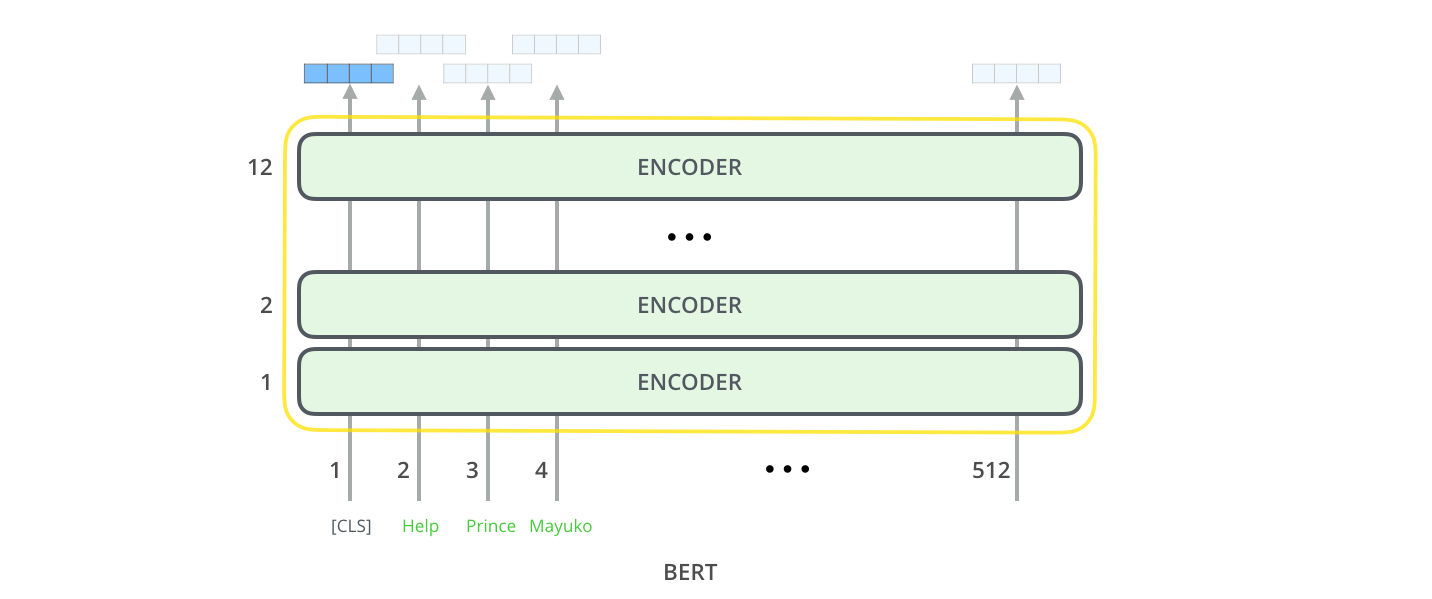
When do I use this?
- Embeddings: When I’m building a semantic search engine or a RAG (Retrieval-Augmented Generation) pipeline, I use an encoder to convert text into dense vectors.
- Classification: Things like sentiment analysis or spam detection.
- Token Classification: Named Entity Recognition (NER).
If you need to compare the semantic similarity of two documents, an Encoder-based model is your best friend.
3. Decoder-Based Models (e.g., GPT)
On the flip side, if your goal is to generate text, you rely on the Decoder.
Models in the GPT (Generative Pre-trained Transformer) family—which includes the models powering ChatGPT, Claude, and Llama—use a decoder-only architecture.
Unlike encoders, decoders are unidirectional (or autoregressive). When predicting the next word, they are only allowed to look at the words that came before it. They can’t peek into the future.
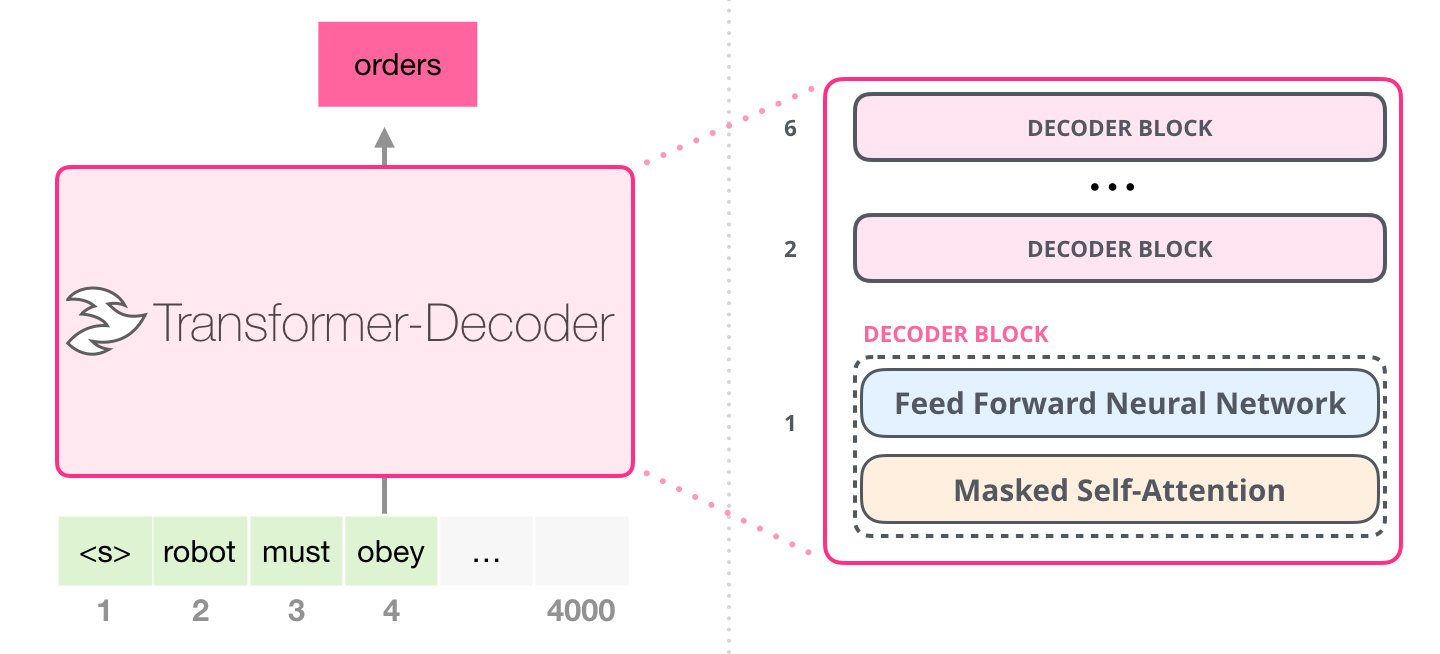
When do I use this?
- Chatbots & Conversational AI: Building interactive assistants.
- Text Generation: Writing code, drafting emails, creative writing.
- Reasoning: Chain-of-thought prompting for complex problem solving.
Because they are trained to predict the next token across massive amounts of internet text, decoder models have emerged as incredibly versatile general-purpose AI assistants.
4. How Decoder Inference Actually Works: Prefill and Decoding
Here’s a detail that I found super fascinating: when you send a prompt to ChatGPT, the model doesn’t just read your prompt and instantly spit out the whole answer.
The inference (generation) process is actually split into two distinct phases: Prefill and Decoding.
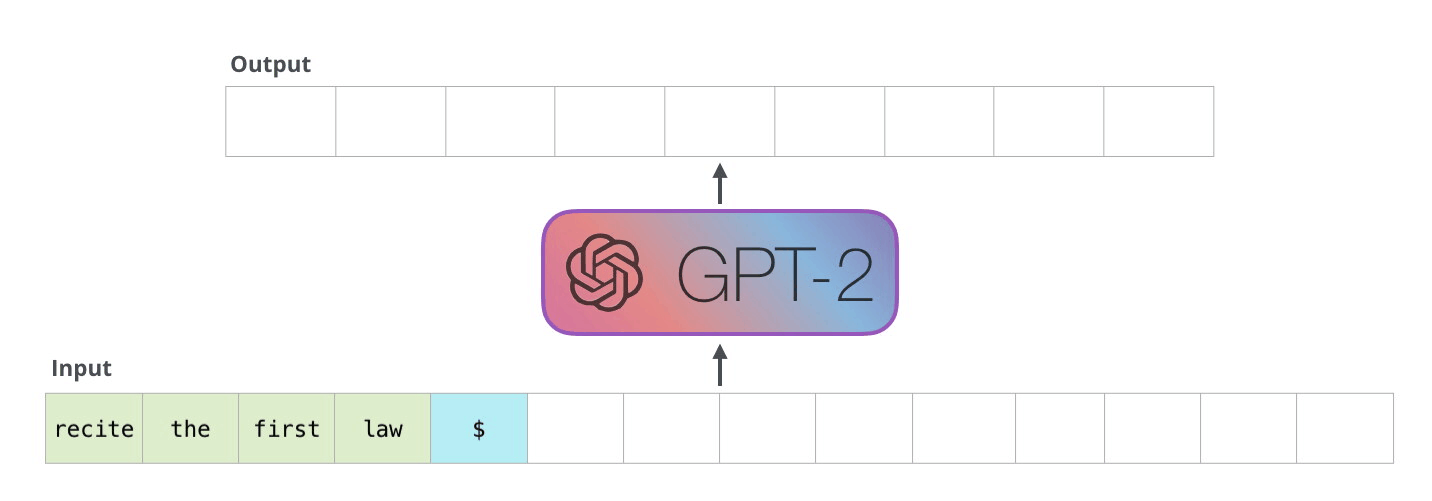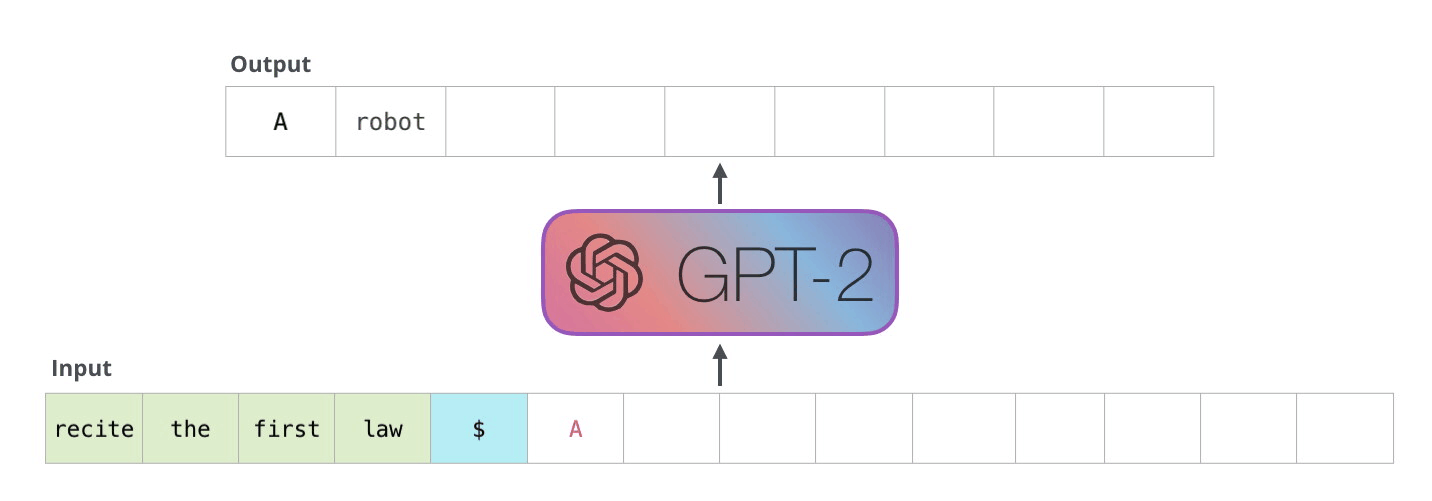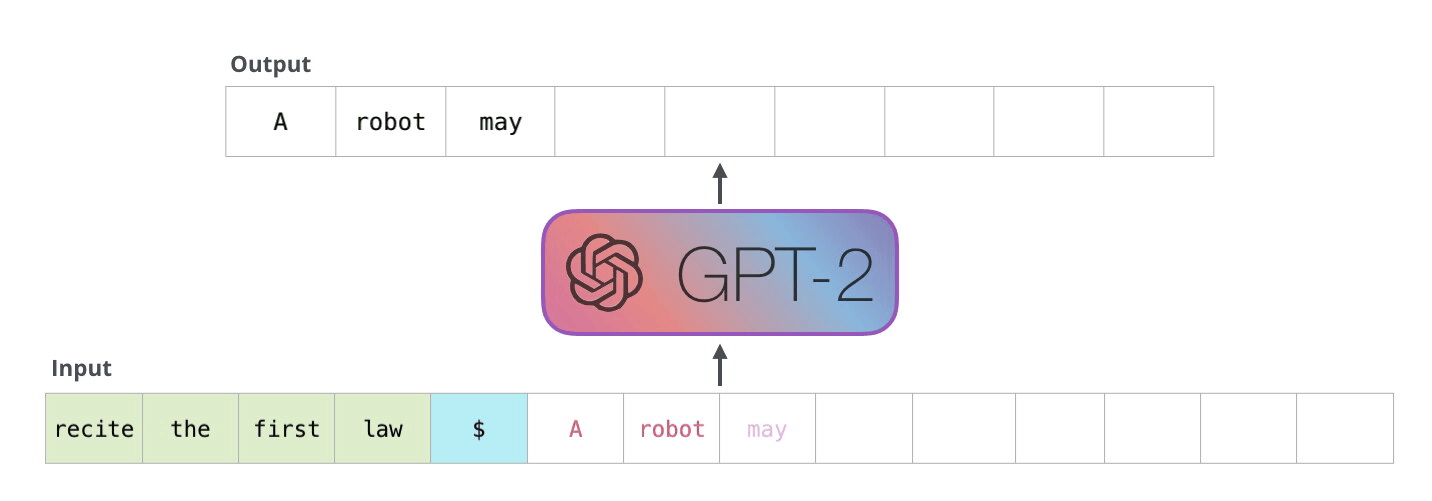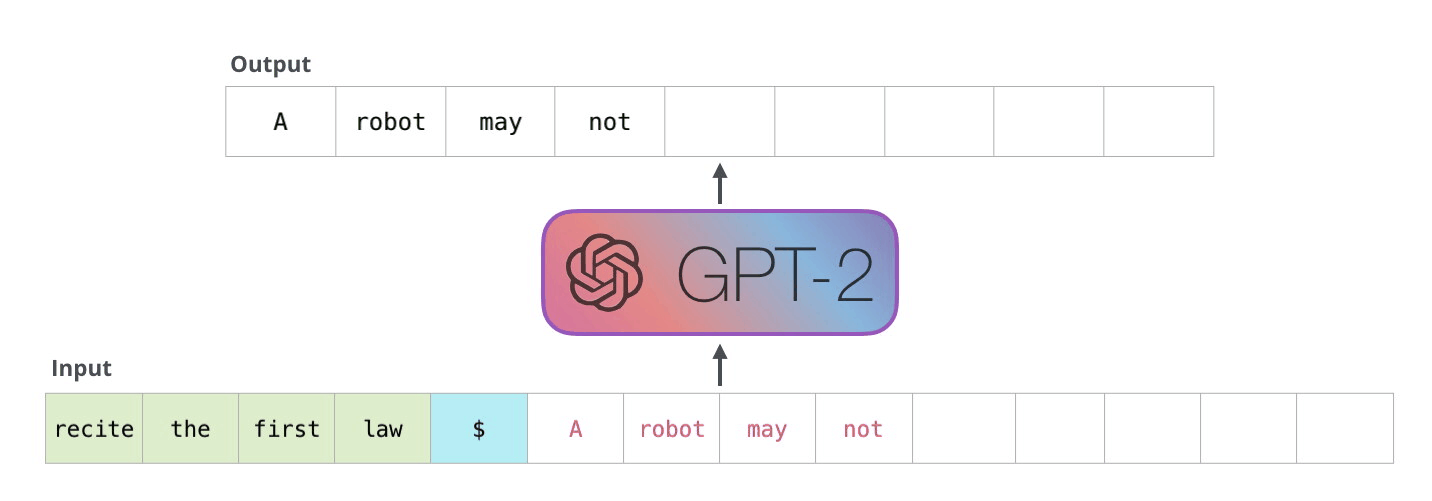
Phase 1: The Prefill Phase
In this first step, the LLM takes your entire input prompt and processes it all at once (in parallel).
- What’s happening: The model computes the “Key-Value (KV) Cache” for your prompt. It’s essentially building its internal understanding of everything you just said.
- Why it matters: This phase is highly parallelizable. It happens very quickly, which is why the “Time to First Token” (TTFT) is usually just a fraction of a second, even if you paste in a massive document.
Phase 2: The Decoding (Autoregressive) Phase
Once the prompt is processed, the model starts generating the response.
- What’s happening: The model predicts the first word of the answer. Then, it takes that new word, appends it to its internal memory (the KV Cache), and uses it to predict the next word. This loop repeats until the model generates a special “Stop” token.
- Why it matters: This phase is strictly sequential. You cannot predict word #5 until you have predicted word #4.
Because it requires loading the massive model weights into memory for every single word generated, this phase is memory-bandwidth bound and much slower than the prefill phase.
Wrapping Up
Understanding the difference between these architectures has really helped me pick the right tool for the job:
- Need to search, cluster, or embed text? Reach for an Encoder (BERT).
- Need to generate text, write code, or build a chatbot? Reach for a Decoder (GPT).
- Need to do complex translation or summarization? An Encoder-Decoder (T5) might be the perfect fit.
Next time you watch a chatbot stream its answer to you word-by-word, you’ll know exactly what’s happening behind the scenes: a lightning-fast prefill followed by a sequential, autoregressive decoding loop!
Putting it together
The architecture choice — encoder-only, decoder-only, or encoder-decoder — is really a choice about what the model needs to know at generation time. Encoders see everything; decoders see only the past; encoder-decoders separate understanding from generation. For most applications today, decoder-only models (the GPT family) have won because scale and RLHF have made them surprisingly good at tasks that look like they’d need bidirectional context. But understanding why each architecture exists makes it easier to reason about when the exceptions still apply.